大数据学习
bigdata learning
Toggle navigation
大数据学习
主页
openGauss数据库
Flume
MongoDB
Hadoop
数据库实验
Kafka
Zookeeper
Hbase
Manual
Spark
Neo4j
InfluxDB
RabbitMQ
Flink
About Me
归档
标签
04-HBase-命令行操作实例-01
HBase
2025-03-31 22:54:57
80
0
0
bigdata
HBase
#**实例简述** 本节将在命令行HBase环境下创建employee表,其包含两个列族:personal_data和professional_data,其中personal_data包含name,age两个限定符记录员工个人信息,professional_data包含position限定符记录员工职位。 #**实验环境** 本实验在ecs服务器上进行,采用HBase伪分布式模式,已开启Hadoop和HBase,开启流程见 (01-HBase安装),通过命令 ``` hbase shell ``` 进入hbase命令行模式(由于在01-HBase安装中配置了环境变量,所以该命令可以在任意文件夹下使用) ###**创建employee表** 使用create命令创建表: ``` create 'employee', 'personal_data', 'professional_data' ``` 命令执行如下:  该命令创建了'employee'表,属性有'personal_data'和'professional_data'。创建完后,使用describe命令查看表信息:  ###**插入数据** 使用put命令插入数据: ``` put 'employee', '1', 'personal_data:name', 'John' put 'employee', '1', 'personal_data:age', '30' put 'employee', '1', 'professional_data:position', 'Manager' put 'employee', '2', 'personal_data:name', 'Jane' put 'employee', '2', 'personal_data:age', '35' put 'employee', '2', 'professional_data:position', 'Engineer' put 'employee', '3', 'personal_data:name', 'Alice' put 'employee', '3', 'personal_data:age', '28' put 'employee', '3', 'professional_data:position', 'Analyst' ``` 命令运行如下: 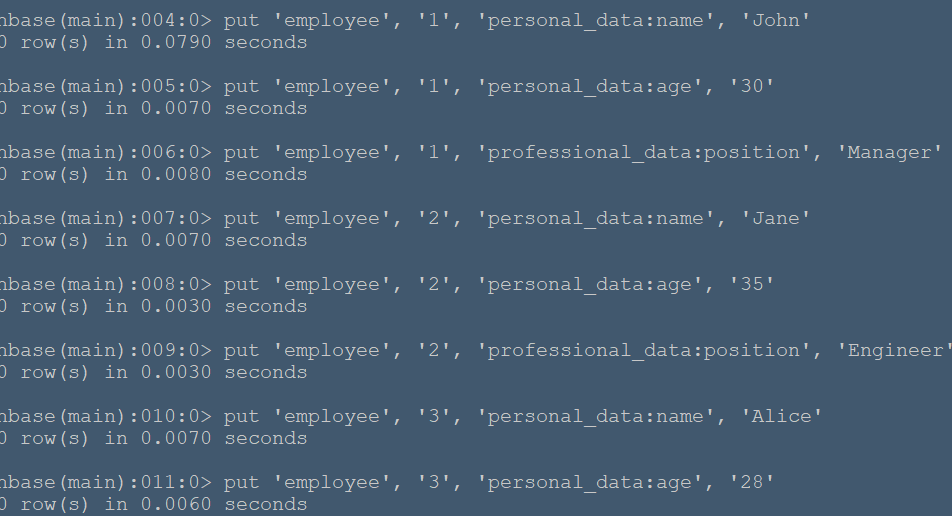 在表中我们插入了三个人的详细信息,职业分别是Manager,Engineer,Analyst,并插入了每个人的具体姓名和年龄。 ###**数据查询** 我们可以使用get命令和scan命令确认插入操作: ``` get 'employee','1' scan 'employee' ``` 命令运行如下: 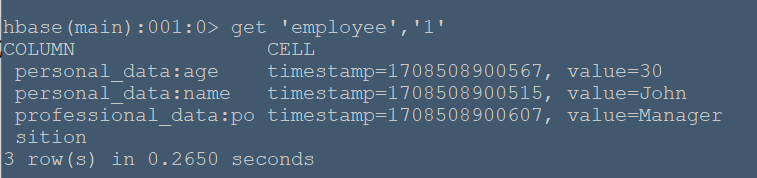 get 命令获取了行键为'1'的所有数据 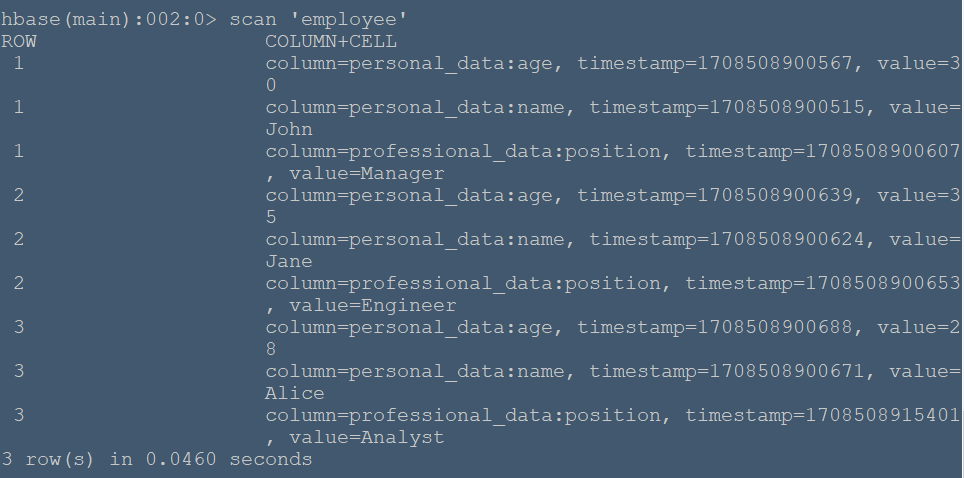 scan命令获取了表中的所有数据 ###**数据过滤** 在scan命令中加入FILTER关键字过滤查询结果: ``` # 过滤数据 scan 'employee', {FILTER => "SingleColumnValueFilter('personal_data', 'age', >, 'binary:30')"} ``` 命令执行如下: 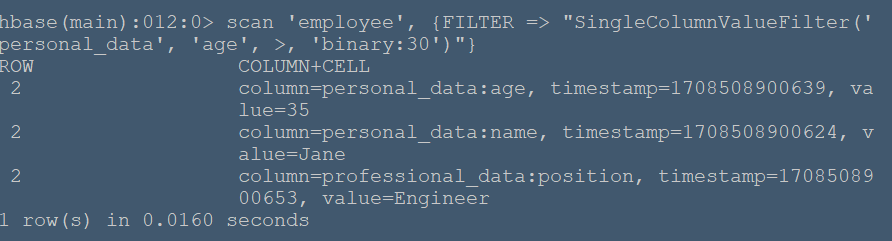 该命令查询表中personal_data列族下age限定符大于30的数据信息。 ###**删除数据** 使用delete命令删除某个单元格数据: ``` delete 'employee', '1', 'personal_data:name' ``` 执行结果: 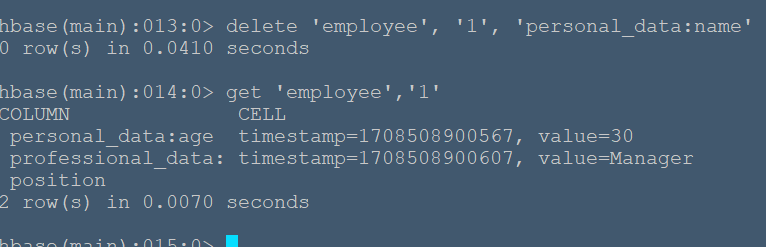 可以看到name属性被删除了。
上一篇:
04-Flume案列-实时监控单个追加文件
下一篇:
04-Hadoop-HDFS-JavaApi-Maven
文档导航

 浙ICP备案2024056857号
浙ICP备案2024056857号
 浙公网安备33020502001085号
浙公网安备33020502001085号