大数据学习
bigdata learning
Toggle navigation
大数据学习
主页
openGauss数据库
Flume
MongoDB
Hadoop
数据库实验
Kafka
Zookeeper
Hbase
Manual
Spark
Neo4j
InfluxDB
RabbitMQ
Flink
About Me
归档
标签
04-Flume案列-实时监控单个追加文件
Flume
2022-09-27 17:18:27
79
0
0
bigdata
Flume
# Flume案例-实时监控单个追加文件 ## 1)案例需求: 实时监控 Hive 日志,并上传到 HDFS 中 ## 2)需求分析: 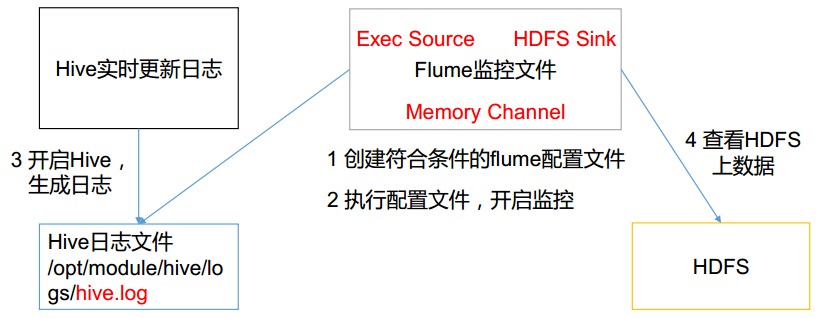 ## 3)实现步骤: ### 1.Flume 要想将数据输出到 HDFS,须持有 Hadoop 相关 jar 包 将 commons-configuration-1.6.jar hadoop-auth-2.7.2.jar hadoop-common-2.7.2.jar hadoop-hdfs-2.7.2.jar commons-io-2.4.jar htrace-core-3.1.0-incubating.jar 拷贝到/usr/local/flume/lib 文件夹下。 ```bash nbu@ecs:~$ cp /usr/local/hadoop/share/hadoop/common/*.jar /usr/local/flume/lib nbu@ecs:~$ cp /usr/local/hadoop/share/hadoop/common/lib/*.jar /usr/local/flume/lib nbu@ecs:~$ cp /usr/local/hadoop/share/hadoop/hdfs/hadoop-hdfs-2.7.1.jar /usr/local/flume/lib/ ``` > 注意这里的jar文件需要先安装hadoop ### 2.创建 flume-file-hdfs.conf 文件 创建文件 ```bash nbu@ecs:~$ cd /usr/local/flume/job/ nbu@ecs:/usr/local/flume/job$ vim flume-file-hdfs.conf ``` 注: 要想读取 Linux 系统中的文件,就得按照 Linux 命令的规则执行命令。 由于 Hive 日志 在 Linux 系统中所以读取文件的类型选择: exec 即 execute 执行的意思。 表示执行 Linux 命令来读取文件。 添加如下内容 ```bash # Name the components on this agent a2.sources = r2 a2.sinks = k2 a2.channels = c2 # Describe/configure the source a2.sources.r2.type = exec a2.sources.r2.command = tail -F /usr/local/hive/logs/hive.log a2.sources.r2.shell = /bin/bash -c # Describe the sink a2.sinks.k2.type = hdfs a2.sinks.k2.hdfs.path = hdfs://localhost:9000/flume/%Y%m%d/%H #上传文件的前缀 a2.sinks.k2.hdfs.filePrefix = logs- #是否按照时间滚动文件夹 a2.sinks.k2.hdfs.round = true #多少时间单位创建一个新的文件夹 a2.sinks.k2.hdfs.roundValue = 1 #重新定义时间单位 a2.sinks.k2.hdfs.roundUnit = hour #是否使用本地时间戳 a2.sinks.k2.hdfs.useLocalTimeStamp = true #积攒多少个 Event 才 flush 到 HDFS 一次 a2.sinks.k2.hdfs.batchSize = 1000 #设置文件类型,可支持压缩 a2.sinks.k2.hdfs.fileType = DataStream #多久生成一个新的文件 a2.sinks.k2.hdfs.rollInterval = 30 #设置每个文件的滚动大小 a2.sinks.k2.hdfs.rollSize = 134217700 #文件的滚动与 Event 数量无关 a2.sinks.k2.hdfs.rollCount = 0 # Use a channel which buffers events in memory a2.channels.c2.type = memory a2.channels.c2.capacity = 1000 a2.channels.c2.transactionCapacity = 100 # Bind the source and sink to the channel a2.sources.r2.channels = c2 a2.sinks.k2.channel = c2 ``` 注意: 对于所有与时间相关的转义序列, Event Header 中必须存在以 “timestamp”的 key(除非 hdfs.useLocalTimeStamp 设置为 true,此方法会使用 TimestampInterceptor 自动添加 timestamp)。 ```bash a3.sinks.k3.hdfs.useLocalTimeStamp = true ```  ### 3.运行 Flume ```bash nbu@ecs:/usr/local/flume/job$ cd .. nbu@ecs:/usr/local/flume$ bin/flume-ng agent --conf conf/ --name a2 --conf-file job/flume-file-hdfs.conf ``` 注意: 可以加上 -Dflume.root.logger=INFO,consol来查看错误信息 ```bash bin/flume-ng agent --conf conf/ --name a2 --conf-file job/flume-file-hdfs.conf -Dflume.root.logger=INFO,console ``` ### 4.开启 Hadoop 和 Hive 并操作 Hive 产生日志 ```bash nbu@ecs:~$ cd /usr/local/hadoop/ nbu@ecs:/usr/local/hadoop$ sbin/start-dfs.sh nbu@ecs:/usr/local/hadoop$ sbin/start-yarn.sh nbu@ecs:/usr/local/hadoop$ cd /usr/local/hive/ nbu@ecs:/usr/local/hive$ bin/hive hive (default)> ``` 注意: 如果出现“Cannot find hadoop installation: $HADOOP_HOME or $HADOOP_PREFIX must be set or hadoop must be in the path” 需要在 ```bash nbu@ecs:~$ cd /usr/local/hive/conf/ nbu@ecs:/usr/local/hive/conf$ cp hive-env.sh.template hive-env.sh nbu@ecs:/usr/local/hive/conf$ vi hive-env.sh #添加如下语句 export HADOOP_HOME=/usr/local/hadoop nbu@ecs:/usr/local/hive/conf$ source hive-env.sh ``` ### 5.在 HDFS 上查看文件。 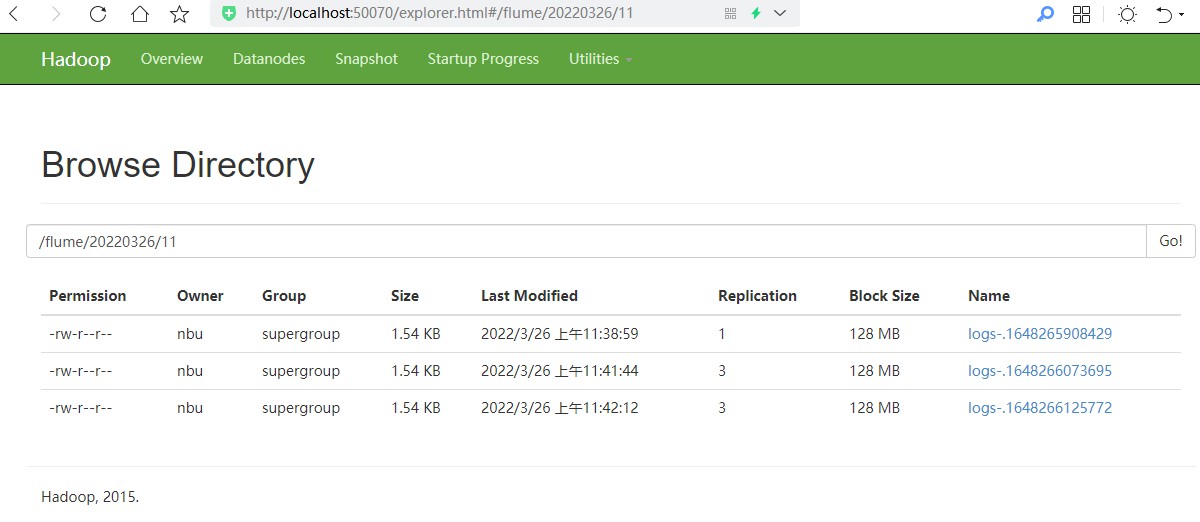
上一篇:
04 openGauss数据库安全指导手册
下一篇:
04-HBase-命令行操作实例-01
文档导航

 浙ICP备案2024056857号
浙ICP备案2024056857号
 浙公网安备33020502001085号
浙公网安备33020502001085号