大数据学习
bigdata learning
Toggle navigation
大数据学习
主页
openGauss数据库
Flume
MongoDB
Hadoop
数据库实验
Kafka
Zookeeper
Hbase
Manual
Spark
Neo4j
InfluxDB
RabbitMQ
Flink
About Me
归档
标签
05-HBase-命令行操作实例-02
无
2025-03-31 22:54:57
31
0
0
bigdata
#**实例简述** 本节将在04-HBase-命令行操作实例-01基础上测试更多查询命令。 #**实验环境** 本实验在ecs服务器上进行,采用HBase伪分布式模式,已开启Hadoop和HBase,开启流程见 (01-HBase安装),表内容见04-HBase-命令行操作实例-01。 ###**查询特定列族数据** 使用scan命令查询特定列族的数据: ``` scan 'employee', {COLUMNS => 'personal_data'} ``` 命令运行结果如下: 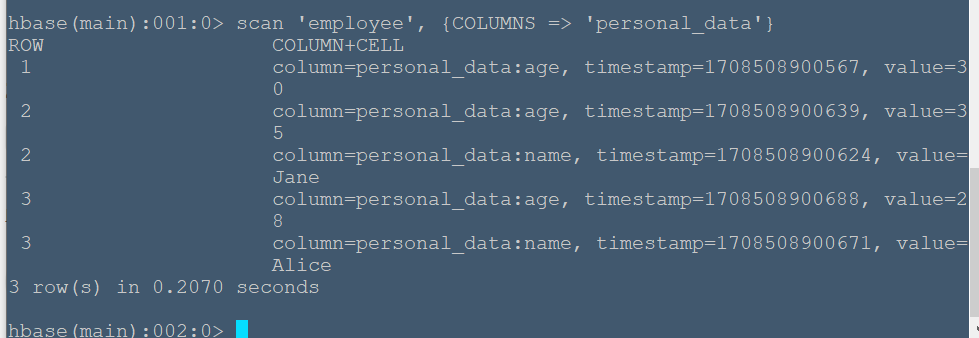 可以看到行键为1中只有age而没有name,原因是因为在04-HBase-命令行操作实例-01中我们将行键为1的personal_data中的name列族删除了。 ###**查询特定列族中特定列数据** ``` scan 'employee', {COLUMNS => ['personal_data:name', 'personal_data:age']} ``` 命令运行结果: 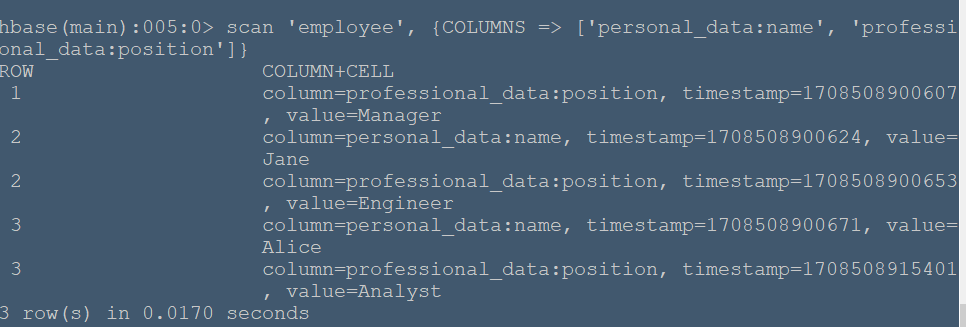 ###**查询特定列族中特定列的数据,并设置起始行和结束行** 使用STARTROW和ENDROW关键字限定起始和结束行 ``` scan 'employee', {COLUMNS => ['personal_data:name', 'personal_data:age'], STARTROW => '1', ENDROW => '3'} ``` 命令运行结果: 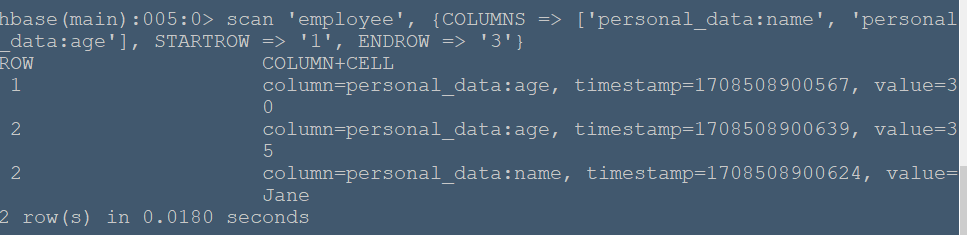 可以看到返回了行键为1和2的数据,所以hbase返回的是[1,3)行的数据。 ###**查询数据并限定返回行数** 使用LIMIT关键字限定返回行数 ``` scan 'employee', {LIMIT => 1} ``` 命令运行结果:  可以看到只返回一行的数据。
上一篇:
05-Flume案例-实时监控目录下的多个追加文件
下一篇:
05-Hadoop-MapReduce编程-javac
文档导航

 浙ICP备案2024056857号
浙ICP备案2024056857号
 浙公网安备33020502001085号
浙公网安备33020502001085号