大数据学习
bigdata learning
Toggle navigation
大数据学习
主页
openGauss数据库
Flume
MongoDB
Hadoop
数据库实验
Kafka
Zookeeper
Hbase
Manual
Spark
Neo4j
InfluxDB
RabbitMQ
Flink
About Me
归档
标签
05-Hadoop-MapReduce编程-javac
Hadoop
HDFS
2022-10-13 13:21:43
145
0
0
bigdata
Hadoop
HDFS
# 编译、打包 Hadoop MapReduce 程序 将 Hadoop 的 classhpath 信息添加到 CLASSPATH 变量中,在 ~/.bashrc 中增加如下几行: ```bash export HADOOP_HOME=/usr/local/hadoop export CLASSPATH=$($HADOOP_HOME/bin/hadoop classpath):$CLASSPATH ``` 修改.bashrc文件后,执行 `source ~/.bashrc` 使变量生效。 ```bash nbu@ecs:~$ mkdir -p bigdata/mapreduce/ nbu@ecs:~$ cd bigdata/mapreduce/ nbu@ecs:~/bigdata/mapreduce$ vim WordCount.java ``` WordCount.java 内容如下: ```java import java.io.IOException; import java.util.Iterator; import java.util.StringTokenizer; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.util.GenericOptionsParser; public class WordCount { public WordCount() { } public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); String[] otherArgs = (new GenericOptionsParser(conf, args)).getRemainingArgs(); if (otherArgs.length < 2) { System.err.println("Usage: wordcount <in> [<in>...] <out>"); System.exit(2); } Job job = Job.getInstance(conf, "word count"); job.setJarByClass(WordCount.class); job.setMapperClass(WordCount.TokenizerMapper.class); job.setCombinerClass(WordCount.IntSumReducer.class); job.setReducerClass(WordCount.IntSumReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); for (int i = 0; i < otherArgs.length - 1; ++i) { FileInputFormat.addInputPath(job, new Path(otherArgs[i])); } FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length - 1])); System.exit(job.waitForCompletion(true) ? 0 : 1); } public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> { private IntWritable result = new IntWritable(); public IntSumReducer() { } public void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException { int sum = 0; IntWritable val; for (Iterator i$ = values.iterator(); i$.hasNext(); sum += val.get()) { val = (IntWritable) i$.next(); } this.result.set(sum); context.write(key, this.result); } } public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> { private static final IntWritable one = new IntWritable(1); private Text word = new Text(); public TokenizerMapper() { } public void map(Object key, Text value, Mapper<Object, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException { StringTokenizer itr = new StringTokenizer(value.toString()); while (itr.hasMoreTokens()) { this.word.set(itr.nextToken()); context.write(this.word, one); } } } } ``` ```bash nbu@ecs:~/bigdata/mapreduce$ javac WordCount.java ``` 编译后可以看到生成了几个 .class 文件。  接着把 .class 文件打包成 jar,才能在 Hadoop 中运行: ```bash nbu@ecs:~/bigdata/mapreduce$ jar -cvf WordCount.jar ./WordCount*.class added manifest adding: WordCount.class(in = 1911) (out= 1044)(deflated 45%) adding: WordCount$IntSumReducer.class(in = 1744) (out= 742)(deflated 57%) adding: WordCount$TokenizerMapper.class(in = 1740) (out= 756)(deflated 56%) ``` 打包完成后,运行试试,创建几个输入文件: ```bash nbu@ecs:~/bigdata/mapreduce$ mkdir input nbu@ecs:~/bigdata/mapreduce$ echo "hello world" > ./input/file0 nbu@ecs:~/bigdata/mapreduce$ echo "Ningbo University" > ./input/file1 ``` ```bash # 把本地文件上传到伪分布式HDFS上 nbu@ecs:~/bigdata/mapreduce$ /usr/local/hadoop/bin/hdfs dfs -put ./input input_mr ``` 开始运行mapreduce ```bash nbu@ecs:~/bigdata/mapreduce$ /usr/local/hadoop/bin/hadoop jar WordCount.jar WordCount input_mr output ``` 成功运行如下:  ```bash #查看HDFS中/user/nbu/output的文件 nbu@ecs:~/bigdata/mapreduce$ /usr/local/hadoop/bin/hdfs dfs -ls /user/nbu/output 22/10/28 23:35:13 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Found 2 items -rw-r--r-- 1 nbu supergroup 0 2022-10-28 23:32 /user/nbu/output/_SUCCESS -rw-r--r-- 1 nbu supergroup 38 2022-10-28 23:32 /user/nbu/output/part-r-00000 ``` ```bash #查看 /user/nbu/output/part-r-00000中的内容 nbu@ecs:~/bigdata/mapreduce$ /usr/local/hadoop/bin/hdfs dfs -cat /user/nbu/output/part-r-00000 ``` 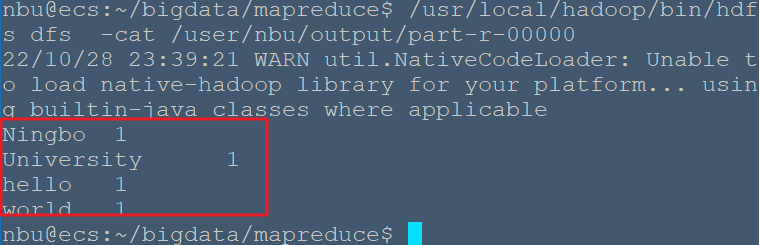 ## 参考资料 - <http://blog.sina.com.cn/s/blog_68cceb610101r6tg.html> - http://www.cppblog.com/humanchao/archive/2014/05/27/207118.aspx
上一篇:
05-HBase-命令行操作实例-02
下一篇:
05-Hive表创建-修改-删除
文档导航

 浙ICP备案2024056857号
浙ICP备案2024056857号
 浙公网安备33020502001085号
浙公网安备33020502001085号