大数据学习
bigdata learning
Toggle navigation
大数据学习
主页
openGauss数据库
Flume
MongoDB
Hadoop
数据库实验
Kafka
Zookeeper
Hbase
Manual
Spark
Neo4j
InfluxDB
RabbitMQ
Flink
About Me
归档
标签
05-Flume案例-实时监控目录下的多个追加文件
Flume
2022-09-27 17:21:43
94
0
0
bigdata
Flume
# Flume案例-实时监控目录下的多个追加文件 Exec source 适用于监控一个实时追加的文件, 但不能保证数据不丢失; Spooldir Source 能够保证数据不丢失,且能够实现断点续传, 但延迟较高,不能实时监控;而 Taildir Source既能够实现断点续传,又可以保证数据不丢失,还能够进行实时监控。 ## 1)案例需求: 使用 Flume 监听整个目录的实时追加文件,并上传至 HDFS ## 2) 需求分析: 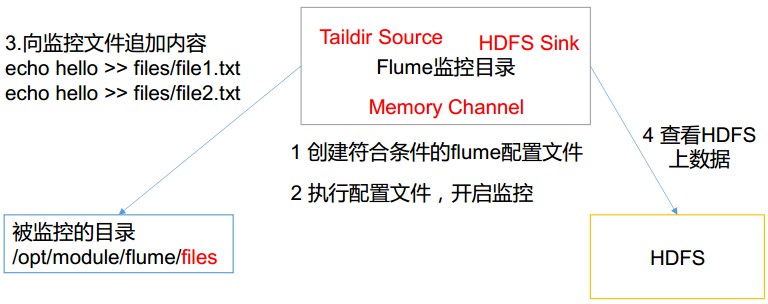 ## 3)实现步骤: ### 1.创建配置文件 flume-taildir-hdfs.conf 创建一个文件 ```bash nbu@ecs:~$ cd /usr/local/flume/job nbu@ecs:/usr/local/flume/job$ vim flume-taildir-hdfs.conf ``` 添加如下内容 ```bash a3.sources = r3 a3.sinks = k3 a3.channels = c3 # Describe/configure the source a3.sources.r3.type = TAILDIR a3.sources.r3.positionFile = /usr/local/flume/tail_dir.json a3.sources.r3.filegroups = f1 a3.sources.r3.filegroups.f1 = /usr/local/flume/files/file.* # Describe the sink a3.sinks.k3.type = hdfs a3.sinks.k3.hdfs.path = hdfs://localhost:9000/flume/upload/%Y%m%d/%H #上传文件的前缀 a3.sinks.k3.hdfs.filePrefix = upload- #是否按照时间滚动文件夹 a3.sinks.k3.hdfs.round = true #多少时间单位创建一个新的文件夹 a3.sinks.k3.hdfs.roundValue = 1 #重新定义时间单位 a3.sinks.k3.hdfs.roundUnit = hour #是否使用本地时间戳 a3.sinks.k3.hdfs.useLocalTimeStamp = true #积攒多少个 Event 才 flush 到 HDFS 一次 a3.sinks.k3.hdfs.batchSize = 100 #设置文件类型,可支持压缩 a3.sinks.k3.hdfs.fileType = DataStream #多久生成一个新的文件 a3.sinks.k3.hdfs.rollInterval = 60 #设置每个文件的滚动大小大概是 128M a3.sinks.k3.hdfs.rollSize = 134217700 #文件的滚动与 Event 数量无关 a3.sinks.k3.hdfs.rollCount = 0 # Use a channel which buffers events in memory a3.channels.c3.type = memory a3.channels.c3.capacity = 1000 a3.channels.c3.transactionCapacity = 100 # Bind the source and sink to the channel a3.sources.r3.channels = c3 a3.sinks.k3.channel = c3 ```  ### 2.启动监控文件夹命令 ```bash nbu@ecs:/usr/local/flume/job$ cd .. nbu@ecs:/usr/local/flume$ bin/flume-ng agent --conf conf/ --name a3 --conf-file job/flume-taildir-hdfs.conf ``` 注意: 可以加上 -Dflume.root.logger=INFO,consol来查看错误信息 ```bash bin/flume-ng agent --conf conf/ --name a3 --conf-file job/flume-taildir-hdfs.conf -Dflume.root.logger=INFO,console ``` ### 3.向 files 文件夹中追加内容 在/opt/module/flume 目录下创建 files 文件夹 ```bash nbu@ecs:/usr/local/flume$ mkdir files ``` 向 upload 文件夹中添加文件 ```bash nbu@ecs:/usr/local/flume$ cd files nbu@ecs:/usr/local/flume/files$ echo hello >> file1.txt nbu@ecs:/usr/local/flume/files$ echo nbu >> file2.txt ``` ### 4.查看 HDFS 上的数据 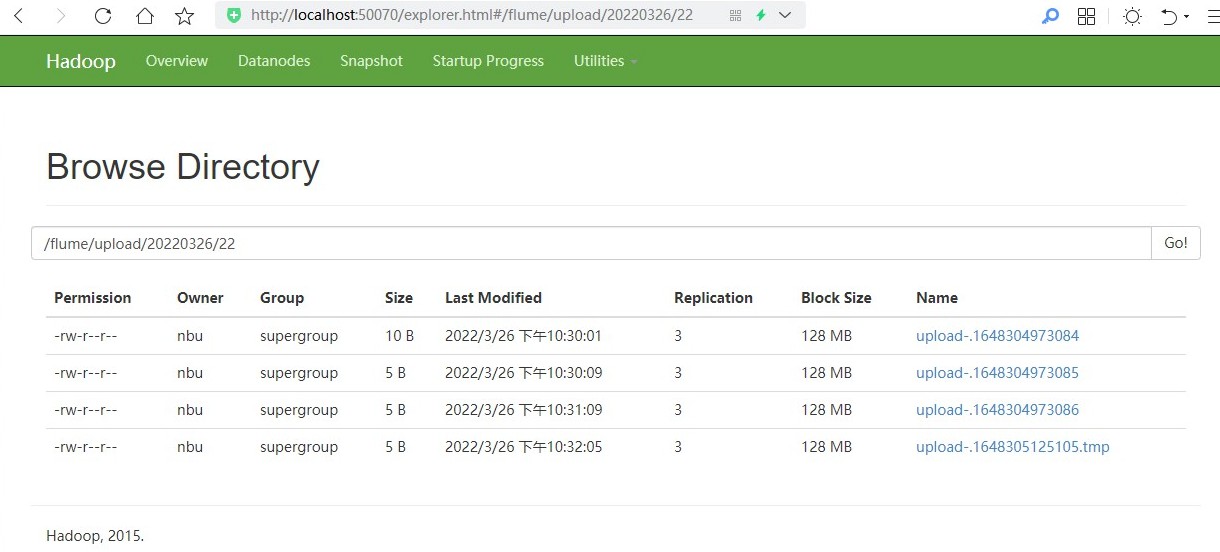 Taildir 说明: Taildir Source 维护了一个 json 格式的 position File,其会定期的往 position File 中更新每个文件读取到的最新的位置,因此能够实现断点续传。Position File 的格式如下: ```json {"inode":2496272,"pos":12,"file":"/usr/local/flume/files/file1.txt"} {"inode":2496275,"pos":12,"file":"/usr/local/flume/files/file2.txt"} ``` 注: Linux 中储存文件元数据的区域就叫做 inode, 每个 inode 都有一个号码,操作系统 用 inode 号码来识别不同的文件, Unix/Linux 系统内部不使用文件名,而使用 inode 号码来识别文件。
上一篇:
05 openGauss使用JDBC连接数据库指导手册
下一篇:
05-HBase-命令行操作实例-02
文档导航

 浙ICP备案2024056857号
浙ICP备案2024056857号
 浙公网安备33020502001085号
浙公网安备33020502001085号