大数据学习
bigdata learning
Toggle navigation
大数据学习
主页
openGauss数据库
Flume
MongoDB
Hadoop
数据库实验
Kafka
Zookeeper
Hbase
Manual
Spark
Neo4j
InfluxDB
RabbitMQ
Flink
About Me
归档
标签
02 openGauss数据库开发调试工具指导手册
openGauss数据库
2022-10-15 14:14:08
26
0
0
bigdata
openGauss数据库
# **1 客户端工具** ## 1.1 实验介绍 ### 1.1.1 关于本实验 本实验主要描述openGauss数据库的客户端工具的使用和连接数据库的方法。 ### 1.1.2 实验目的 * 掌握gsql客户端工具本地连接数据库的方法; * 掌握gsql客户端工具远程连接数据库的方法; * 掌握gsql客户端工具使用方法; * 掌握图形化界面客户端工具Data Studio的安装及使用方法。 ## 1.2 gsql客户端工具 gsql是openGauss提供在命令行下运行的数据库连接工具,可以通过此工具连接服务器并对其进行操作和维护,除了具备操作数据库的基本功能,gsql还提供了若干高级特性,便于用户使用。 ### 1.2.1 gsql连接数据库 gsql是openGauss自带的客户端工具。使用gsql连接数据库,可以交互式地输入、编辑、执行SQL语句。 #### 1.2.1.1 确认连接信息 客户端工具通过数据库主节点连接数据库。因此连接前,需获取数据库主节点所在服务器的IP地址及数据库主节点的端口号信息。 **步骤 1** 切换到omm用户,以操作系统用户omm登录数据库主节点。 > [root@db1 script]# **su - omm** **步骤 2** 使用“gs_om -t status --detail”命令查询openGauss各实例情况。 > [omm@db1 ~]$ **gs_om -t status** **--detail** 情况显示如下: >[ DBnode State ] > >node node_ip instance state >\------------------------------------------------------------------------------------- >1 db1 192.168.0.58 6001 /gaussdb/data/db1 P Primary Normal 如上部署了数据库主节点实例的服务器IP地址为**192.168.0.58**。数据库主节点数据路径为“**/gaussdb/data/db1**”。 **步骤 3 **确认数据库主节点的端口号。 在[**步骤2**](#d0e949)查到的数据库主节点数据路径下的postgresql.conf文件中查看端口号信息。示例如下: > [omm@db1 ~]$ **cat /gaussdb/data/db1/postgresql.conf | grep port** 结果显示如下: >port = 26000** # (change requires restart) > >\#ssl_renegotiation_limit = 0 # amount of data between renegotiations, no longer supported > >\#tcp_recv_timeout = 0 # SO_RCVTIMEO, specify the receiving timeouts until reporting an error(change requires restart) > >\#comm_sctp_port = 1024 # Assigned by installation (change requires restart) > >\#comm_control_port = 10001 # Assigned by installation (change requires restart) > > # supported by the operating system: > > # The heartbeat thread will not start if not set localheartbeatport and remoteheartbeatport. > > # e.g. 'localhost=xx.xx.xxx.2 localport=12211 localheartbeatport=12214 remotehost=xx.xx.xxx.3 remoteport=12212 remoteheartbeatport=12215, localhost=xx.xx.xxx.2 localport=12213 remotehost=xx.xx.xxx.3 remoteport=12214' > > # %r = remote host and port > >alarm_report_interval = 10 **26000**为数据库主节点的端口号。 请在实际操作中记录**数据库主节点实例的服务器**IP地址**,**数据路径和端口号,**并在之后操作中**按照实际情况进行替换。 #### 1.2.1.2 本地连接数据库 **步骤 1 **切换到omm用户,以操作系统用户omm登录数据库主节点。 > [root@db1 script]# **su - omm** **步骤 2** 启动数据库服务 > [root@db1 script]# **gs_om -t start** 显示如下,启动成功。 >Starting cluster. > >========================================= > >========================================= > >Successfully started. **步骤 3** 连接数据库。 执行如下命令连接数据库。 > [omm@db1 ~]$ **gsql -d postgres -p 26000 -r** 其中postgres为需要连接的数据库名称,26000为数据库主节点的端口号。请根据实际情况替换。 连接成功后,系统显示类似如下信息: > gsql ((openGauss 1.0.0 build 290d125f) compiled at 2020-05-08 02:59:43 commit 2143 last mr 131 > Non-SSL connection (SSL connection is recommended when requiring high-security) > Type "help" for help. > > postgres=# omm用户是管理员用户,因此系统显示“DBNAME=#”。若使用普通用户身份登录和连接数据库,系统显示“DBNAME=>”。 “Non-SSL connection”表示未使用SSL方式连接数据库。如果需要高安全性时,请用SSL进行安全的TCP/IP连接。 **步骤 4** 退出数据库。 > postgres=# **\q** ### 1.2.2 gsql获取帮助 #### 1.2.2.1 前提条件 以下操作在openGauss的数据库主节点所在主机上执行(本地连接数据库),切换到omm用户。 > **su - omm** #### 1.2.2.2 连接数据库时,可以使用如下命令获取帮助信息 > **gsql --help** 显示如下帮助信息: >...... >Usage: >gsql [OPTION]... [DBNAME [USERNAME]] > >General options: >-c, --command=COMMAND run only single command (SQL or internal) and exit >-d, --dbname=DBNAME database name to connect to (default: "postgres") >-f, --file=FILENAME execute commands from file, then exit >...... #### 1.2.2.3 连接到数据库后,可以使用如下命令获取帮助信息 **步骤 1** 使用如下命令连接数据库。 > **gsql -d postgres -p 26000 -r** **步骤 2** 输入help指令。 > postgres=#**help** 显示如下帮助信息: >You are using gsql, the command-line interface to gaussdb. >Type: \copyright for distribution terms >\h for help with SQL commands >\? for help with gsql commands >\g or terminate with semicolon to execute query >\q to quit **步骤 3** 查看版权信息。 > postgres=#**\copyright** 显示如下版权信息: > openGauss Database Management System > > Copyright (c) Huawei Technologies Co., Ltd. 2020. All rights reserved. **步骤 4** 查看openGauss支持的所有SQL语句。 > postgres=#**\h** 显示如下信息: >Available help: >ABORT >ALTER AGGREGATE >ALTER APP WORKLOAD GROUP >... ... **步骤 5** 查看CREATE DATABASE命令的参数可使用下面的命令。 > postgres=#**\help CREATE DATABASE** 显示如下帮助信息: >Command: CREATE DATABASE >Description: create a new database >Syntax: >CREATE DATABASE database_name >[ [ WITH ] {[ OWNER [=] user_name ]| > [ TEMPLATE [=] template ]| > [ ENCODING [=] encoding ]| > [ LC_COLLATE [=] lc_collate ]| > [ LC_CTYPE [=] lc_ctype ]| > [ DBCOMPATIBILITY [=] compatibility_type ]| > [ TABLESPACE [=] tablespace_name ]| > [ CONNECTION LIMIT [=] connlimit ]}[...] ]; **步骤 6** 查看gsql支持的命令。 > postgres=# **\?** 显示如下信息: >General > >\copyright show PostgreSQL usage and distribution terms > >\g [FILE] or ; execute query (and send results to file or |pipe) > >\h(\help) [NAME] help on syntax of SQL commands, * for all commands > >\q quit gsql > >... ... **步骤 7** 退出数据库 > postgres=# **\q** ### 1.2.3 gsql命令使用 #### 1.2.3.1 前提条件 以下操作在openGauss的数据库主节点所在主机上执行(本地连接数据库),切换到omm用户。 > **su - omm** #### 1.2.3.2 执行一条字符串命令 gsql命令直接执行一条显示版权信息的字符串命令 > **gsql -d postgres -p 26000 -c "\copyright"** 显示如下,显示后退出gsql环境: > openGauss Database Management System > > Copyright (c) Huawei Technologies Co., Ltd. 2020. All rights reserved > > $ #### 1.2.3.3 使用文件作为命令源而不是交互式输入 **步骤 1** 创建文件夹存放相关文档。 > **mkdir /home/omm/openGauss** **步骤 2** 创建文件,例如文件名为“mysql.sql”,并写入可执行sql语句“select * from pg_user;”。 > **vi /home/omm/openGauss/mysql.sql** 文件打开输入i,进入INSERT模式,输入” select * from pg_user;”。 > **select \* from pg_user;** 然后点击ESC,输入“:wq”保存文档并退出。 **步骤 3** 执行如下命令使用文件作为命令源。 > **gsql -d postgres -p 26000 -f /home/omm/openGauss/mysql.sql** 结果如下,并且gsql将在处理完文件后结束: >usename | usesysid | usecreatedb | usesuper | usecatupd | userepl | passwd | valbegin | valuntil | respool | parent | spacel > >imit | useconfig | nodegroup | tempspacelimit | spillspacelimit > >---------+----------+-------------+----------+-----------+---------+----------+----------+----------+--------------+--------+------- > >-----+-----------+-----------+----------------+----------------- > >omm | 10 | t | t | t | t | ******** | | | default_pool | 0 | > >| | | | > >jack | 16385 | f | f | f | f | ******** | | | default_pool | 0 | > >| | | | > >(2 rows) > > > >total time: 3 ms **步骤 4** 如果FILENAME是-(连字符),则从标准输入读取。 >gsql -d postgres -p 26000 -f -** > >postgres=# **select \* from pg_user;** > >usename | usesysid | usecreatedb | usesuper | usecatupd | userepl | passwd | valbegin | valuntil | respool | parent | spacel > >imit | useconfig | nodegroup | tempspacelimit | spillspacelimit > >---------+----------+-------------+----------+-----------+---------+----------+----------+----------+--------------+--------+------- > >-----+-----------+-----------+----------------+----------------- > >omm | 10 | t | t | t | t | ******** | | | default_pool | 0 | > >| | | | > >joe | 16385 | f | f | f | f | ******** | | | default_pool | 0 | > >| | | | > >(2 rows) **步骤 5 **退出数据库连接。 > postgres=# **\q** > > total time: 174163 ms #### 1.2.3.4 列出所有可用的数据库(\l的l表示list) > **gsql -d postgres -p 26000 -l** 结果如下,并且gsql将在显示后结束: > List of databases > > Name | Owner | Encoding | Collate | Ctype | Access privileges > > -----------+-------+-----------+---------+-------+------------------- > > db_tpcc | joe | SQL_ASCII | C | C | > > postgres | omm | SQL_ASCII | C | C | > > template0 | omm | SQL_ASCII | C | C | =c/omm + > > | | | | | omm=CTc/omm > > template1 | omm | SQL_ASCII | C | C | =c/omm + > > | | | | | omm=CTc/omm > > (4 rows) > > $ #### 1.2.3.5 设置gsql变量NAME为VALUE **步骤 1** 设置foo的值为bar。 > **gsql -d postgres -p 26000 -v foo=bar** **步骤 2** 在数据库能够显示foo的值。 > postgres=# **\echo :foo** > > bar **步骤 3 **退出数据库连接。 > postgres=> **\q** #### 1.2.3.6 打印gsql版本信息。 > **gsql -V** 结果如下,并且gsql将在显示后结束: > gsql (openGauss 1.0.0 build 0bd0ce80) compiled at 2020-06-30 18:19:23 commit 0 last mr #### 1.2.3.7 使用文件作为输出源 **步骤 1** 创建文件,例如文件名为“output.txt”。 > **touch /home/omm/openGauss/output.txt** **步骤 2 **执行如下命令,除了正常的输出源之外,把所有查询输出记录到文件中。 > **gsql -d postgres -p 26000 -L /home/omm/openGauss/output.txt** 进入gsql环境,输入以下语句: >postgres=# **create table mytable (firstcol int);** > >CREATE TABLE > >postgres=# **insert into mytable values(100);** > >INSERT 0 1 > >postgres=# **select \* from mytable ;** > >firstcol > >\---------- > >100 > >(1 row) > >postgres=# **\q **步骤 3** 查看“output.txt”文档中的内容如下: > **cat /home/omm/openGauss/output.txt** 显示如下: > ********* QUERY ********** > > create table mytable (firstcol int); > CREATE TABLE > > ********* QUERY ********** > > insert into mytable values(100); ************************** > INSERT 0 1 > > ********* QUERY ********** > > select * from mytable; ************************** > firstcol > ---------- > 100 > > (1 row) #### 1.2.3.8 将所有查询输出重定向到文件FILENAME **步骤 1** 创建文件,例如文件名为“outputOnly.txt”。 > **touch** **/home/omm/openGauss/outputOnly.txt** **步骤 2** 执行如下命令。 > **gsql -d postgres -p 26000** **-****o /home/omm/openGauss/outputOnly.txt** **步骤 3** 进入gsql环境,输入以下语句: >postgres=# **drop table mytable;** > >postgres=# **create table mytable (firstcol int);** > >postgres=# **insert into mytable values(100);** > >postgres=# **select \* from mytable;** > >postgres=# **\q** 所有操作都没有回显。 **步骤 4** 查看“outputOnly.txt”文档中的内容如下: > **cat /home/omm/openGauss/outputOnly.txt** 显示如下: >DROP TABLE > >CREATE TABLE > >INSERT 0 1 > >firstcol > >\---------- > >100 > >(1 row) > >"/opt/software/openGauss/output.txt" 8L, 76C #### 1.2.3.9 安静模式 安静模式:执行时不会打印出额外信息 > **gsql -d postgres -p 26000 -q** 进入gsql环境,输入以下语句: >postgres=# **create table t_test (firstcol int);** > >postgres=# **insert into t_test values(200);** > >postgres=# **select \* from t_test;** > >firstcol > >\---------- > >200 > >(1 row) > > > >postgres=# **\q 连接上数据库,创建数据库和插入数据等都没有回显信息。 #### 1.2.3.10 单行运行模式 单行运行模式:这时每个命令都将由换行符结束,像分号那样 > **gsql -d postgres -p 26000 -S** 进入gsql环境,输入以下语句: >postgres^# **select \* from t_test;** > >firstcol > >\---------- > >200 > >(1 row) > > > >postgres^# **select \* from t_test** > >firstcol > >\---------- > >200 > >(1 row) > > > >postgres=# **\q 语句最后结尾有;号和没有;号,效果都一样。 #### 1.2.3.11 编辑模式 **步骤 1** 如下命令连接数据库,开启在客户端操作中可以进行编辑的模式。 > **-d postgres -p 26000 -r** **步骤 2** 进入gsql环境,输入以下语句:  **步骤 3 **写完后**不要按回车**,光标在最后闪烁。  **步骤 4** 按“向左”键讲光标移动到“*”,将“*”修改为“firstcol”。 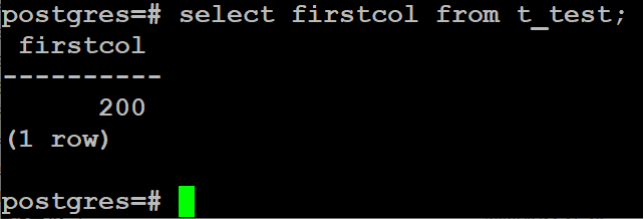 编辑模式“上下左右键”,“删除键”和“退格键”都可以使用,并且按下“向上”、“向下”键可以切换输入过的命令。 **步骤 5 **退出数据库连接 > postgres=# **\q** #### 1.2.3.12 远程使用用户名和密码连接数据库 远程使用jack用户连接ip地址为192.168.0.58端口号为26000的数据库 **步骤 1** 登录客户端主机(192.168.0.58),使用以下命令远程登录数据库。 > **gsql -d postgres -h 192.168.0.58 -U jack -p 26000 -W Bigdata@123;** -d参数指定目标数据库名、-U参数指定数据库用户名、-h参数指定主机名、-p参数指定端口号信息,-W参数指定数据库用户密码。 进入gsql环境,显示如下: >gsql ((openGauss 1.0 build ec0e781b) compiled at 2020-04-27 17:25:57 commit 2144 last mr 131 ) > >SSL connection (cipher: DHE-RSA-AES256-GCM-SHA384, bits: 256) > >Type "help" for help. > > > >postgres=> ### 1.2.4 gsql元命令使用 #### 1.2.4.1 前提条件 以下操作在openGauss的数据库主节点所在主机上执行(本地连接数据库),使用gsql连接到openGauss数据库。 **步骤 1** 切换到omm用户,以操作系统用户omm登录数据库主节点。 > **su - omm** **步骤 2** gsql连接数据库。 > **gsql -d postgres -p 26000 -r** #### 1.2.4.2 打印当前查询缓冲区到标准输出 **步骤 1** 创建“outputSQL.txt”文件。 > **touch /home/omm/openGauss/outputSQL.txt** **步骤 2** 连接数据库。 > **gsql -d postgres -p 26000 -r** **步骤 3** 输入以下语句。 >postgres=# **select \* from pg_roles;** > >rolname | rolsuper | rolinherit | rolcreaterole | rolcreatedb | rolcatupdate | rolcanlogin | rolreplication | rolauditadmin | rolsy > >stemadmin | rolconnlimit | rolpassword | rolvalidbegin | rolvaliduntil | rolrespool | rolparentid | roltabspace | rolconfig | oid > >| roluseft | rolkind | nodegroup | roltempspace | rolspillspace > >---------+----------+------------+---------------+-------------+--------------+-------------+----------------+---------------+------ > >----------+--------------+-------------+---------------+---------------+--------------+-------------+-------------+-----------+----- > >--+----------+---------+-----------+--------------+--------------- > >omm | t | t | t | t | t | t | t | t | t > > | -1 | ******** | | | default_pool | 0 | | | 1 > >0 | t | n | | | > >joe | f | t | f | f | f | t | f | f | f > > | -1 | ******** | | | default_pool | 0 | | | 1725 > >5 | f | n | | | > >(3 rows) > > > >postgres=# **\w /home/omm/openGauss/outputSQL.txt** > >postgres=# **\q **步骤 4** 打开文件“outputSQL.txt”文件,查看其中内容。 > **cat /home/omm/openGauss/outputSQL.txt** 显示如下: > **select \* from pg_roles;** #### 1.2.4.3 导入数据 **步骤 1** 连接数据库。 > **gsql -d postgres -p 26000 -r** **步骤 2** 创建目标表a。 > postgres=# **CREATE TABLE a(a int);** **步骤 3** 导入数据,从stdin拷贝数据到目标表a。 > postgres=# **\copy a from stdin;** 出现>>符号提示时,输入数据,输入\.时结束。 >Enter data to be copied followed by a newline. > >End with a backslash and a period on a line by itself. > >\>> 1 > >\>> 2 > >\>> \. **步骤 4** 查询导入目标表a的数据。 >postgres=# **SELECT \* FROM a;** > >a > >\--- > >1 > >2 退出数据库: > postgres=# **\q** **步骤 5** 从本地文件拷贝数据到目标表a,创建文件/home/omm/openGauss/2.csv。 > **vi /home/omm/openGauss/2.csv** **步骤 6** 输入i,切换到INSERT模式,插入数据如下: >3 > >4 > >5 * 如果有多个数据,分隔符为‘,’。 * 在导入过程中,若数据源文件比外表定义的列数多,则忽略行尾多出来的列。 **步骤 7** 按下Esc键,输入“:wq”后回车,保存并退出。 **步骤 8 **连接数据库。 > **gsql -d postgres -p 26000 -r** **步骤 9** 如下命令拷贝数据到目标表。 >postgres=# **\copy a FROM '/home/omm/openGauss/2.csv' WITH (delimiter',',IGNORE_EXTRA_DATA 'on');** **步骤 10 **查询导入目标表a的数据。 >postgres=# **SELECT \* FROM a;** > >a > >\--- > >1 > >2 > >3 > >4 > >5 > >(5 rows) #### 1.2.4.4 查询表空间 >postgres=# **\db** > >显示如下: > >postgres=> > >List of tablespaces > >Name | Owner | Location > >------------+-------+---------- > >pg_default | omm | > >pg_global | omm | > >(2 rows) #### 1.2.4.5 查询表的属性。 **步骤 1** 创建表customer_t1。 >postgres=# **DROP TABLE IF EXISTS customer_t1;** > >postgres=# **CREATE TABLE customer_t1** > >**(** > >**c_customer_sk integer,** > >**c_customer_id char(5),** > >**c_first_name char(6),** > >**c_last_name char(8)** > >**); **步骤 2** 查询表的属性。 > postgres=# **\d+;** 显示如下: > Schema | Name | Type | Owner | Size | Storage | Description > > --------+-------------+-------+-------+------------+----------------------------------+------------- > > public | customer_t1 | table | omm | 0 bytes | {orientation=row,compression=no} | > > public | mytable | table | omm | 8192 bytes | {orientation=row,compression=no} | > > public | t_test | table | omm | 8192 bytes | {orientation=row,compression=no} | > > public | ta | table | omm | 0 bytes | {orientation=row,compression=no} | > > (4 rows) **步骤 3** 查询表customer_t1的属性。 > postgres=# **\d+ customer_t1;** 显示如下: > Table "public.customer_t1" > > Column | Type | Modifiers | Storage | Stats target | Description > > ---------------+--------------+-----------+----------+--------------+------------- > > c_customer_sk | integer | | plain | | > > c_customer_id | character(5) | | extended | | > > c_first_name | character(6) | | extended | | > > c_last_name | character(8) | | extended | | > > Has OIDs: no > > Options: orientation=row, compression=no #### 1.2.4.6 查询索引信息 **步骤 1** 在表customer_t1上创建索引。 > **create index customer_t1_index1 on customer_t1(c_customer_id);** **步骤 2** 查询索引信息。 > postgres=# **\di+****;** 显示如下: > List of relations > > Schema | Name | Type | Owner | Table | Size | Storage | Description > > --------+--------------------+-------+-------+-------------+------------+---------+------------- > > public | customer_t1_index1 | index | omm | customer_t1 | 8192 bytes | | **步骤 3** 查询customer_t1_index1索引的信息。 > postgres=# **\di+ customer_t1_index1** 显示如下: > List of relations > > Schema | Name | Type | Owner | Table | Size | Storage | Description > > --------+--------------------+-------+-------+-------------+------------+---------+------------- > > public | customer_t1_index1 | index | omm | customer_t1 | 8192 bytes | | #### 1.2.4.7 切换数据库 **步骤 1** 创建数据库。 >DROP DATABASE IF EXISTS db_tpcc02;** > >**CREATE DATABASE db_tpcc02; **步骤 2** 切换数据库。 > postgres=# **\c db_tpcc02;** 显示如下: > Non-SSL connection (SSL connection is recommended when requiring high-security) > > You are now connected to database "db_tpcc" as user "omm". > > db_tpcc=# **步骤 3** 退出数据库: > postgres=# **\q** ## 1.3 Data Studio客户端工具 Data Studio是一个集成开发环境(IDE),帮助数据库开发人员便捷地构建应用程序,以图形化界面形式提供数据库关键特性。 数据库开发人员仅需掌握少量的编程知识,即可使用该工具进行数据库对象操作。Data Studio提供丰富多样的特性,例如: * 创建和管理数据库对象 * 执行SQL语句/脚本 * 编辑和执行PL/SQL语句 * 图形化查看执行计划和开销 * 导出表数据等 创建和管理数据库对象包括: * 数据库 * 模式 * 函数 * 过程 * 表 * 序列 * 索引 * 视图 * 表空间 * 同义词 Data Studio还提供SQL助手用于在“SQL终端”和“PL/SQLViewer”中执行各种查询/过程/函数。 ### 1.3.1 准备连接环境 **步骤 1** 修改数据库的pg_hba.conf文件。 在GS_HOME中查找pg_hba.conf文件,本实验中数据库GS_HOME设置的为/gaussdb/data/db1,实际操作中GS_HOME地址可以查看安装时的配置文件: <PARAM name="dataNode1" value="**/gaussdb/data/db1**"/>。 > [root@db1 ~]# **cd /gaussdb/data/db1** > > [root@ecs-b5cb db1]# **vi pg_hba.conf** 将以下内容添加进pg_hba.conf文件。 > **host all all 0.0.0.0/0 sha256** 具体如下: 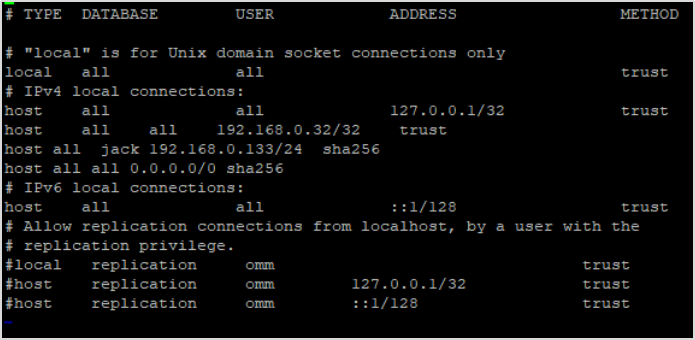 切换至omm用户环境,使用gs_ctl将策略生效。 > [root@db1 db1]#**su - omm** > > [omm@db1 ~]$**gs_ctl reload -D /gaussdb/data/db1/** 返回结果为: > [2020-07-23 15:39:55.398][71828][][gs_ctl]: gs_ctl reload ,datadir is -D "/gaussdb/data/db1" > > server signaled **步骤 2** 登陆数据库并创建“dboper”用户,密码为“**dboper@123**”(密码可自定义),同时进行授权,并退出数据库。 >[omm@db1 ~]$**gsql -d postgres -p 26000 -r** > >postgres=#**CREATE USER dboper IDENTIFIED BY 'dboper@123';** > >CREATE ROLE > >postgres=#**alter user dboper sysadmin;** > >ALTER ROLE > >postgres=# **\q** > >退出OMM用户环境 > >[omm@ecs-b5cb ~]$ **exit** > >logout > >[root@ecs-b5cb ecs-b5cb]# **步骤 3** 修改数据库监听地址。 在GS_HOME中,本实验中数据库GS_HOME设置的为/gaussdb/data/db1。 > [root@ecs-b5cb ecs-b5cb]# **cd /gaussdb/data/db1** > > [root@db1 ~]# **vi postgresql.conf** 将listen_addresses的值修改成为 * 。 > **listen_addresses = '\*'** 修改完成后切换至OMM用户环境重启数据库生效(-D后面的数据库默认路径,需要根据实际情况进行修改)。 > [root@db1 db1]#**su - omm** > > [omm@db1 ~]$**gs_ctl restart -D /gaussdb/data/db1/** ### 1.3.2 确定26000端口是否放开 **步骤 1** 打开华为云首页,登录后进入“控制台”,点击“弹性云服务器ECS”进入ECS列表。  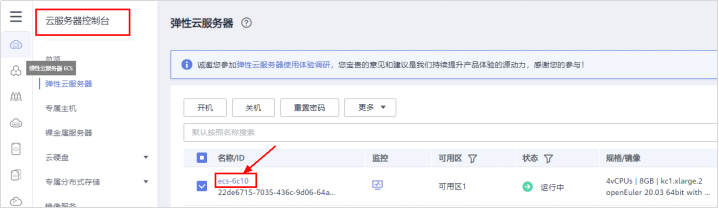 **步骤 2** 在云服务器控制台找到安装数据库主机的ECS,点击查看基本信息,找到安全组。 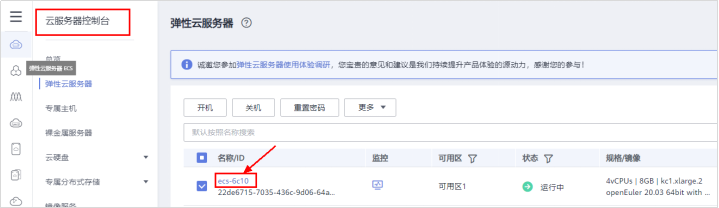 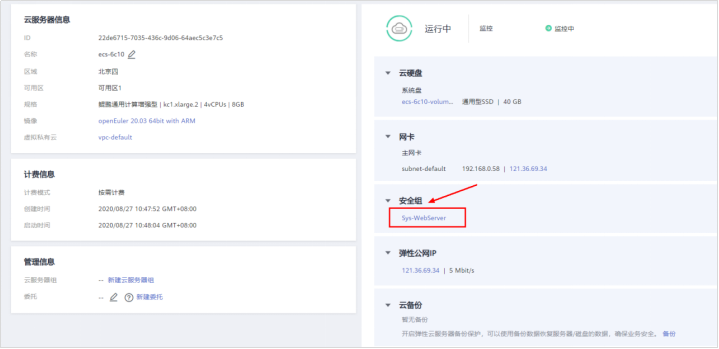 **步骤 3** 点击进入安全组,选择“入方向规则”并点“添加规则”,进行26000端口设置。 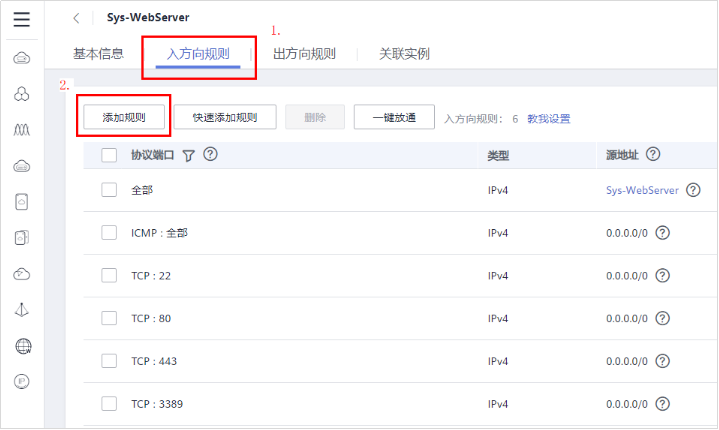 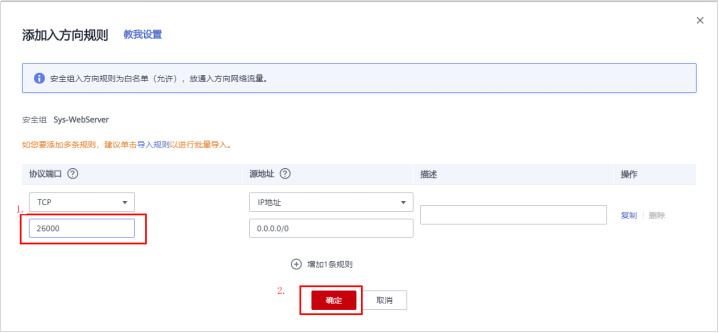 确定后,可以看到入网规则多了**“TCP:26000”**,如下图: 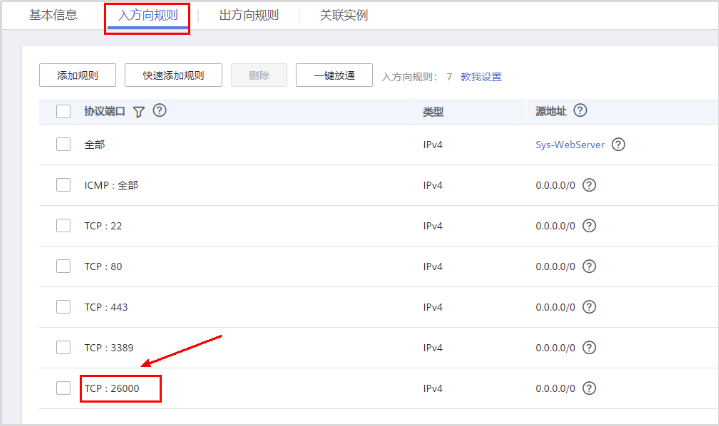 ### 1.3.3 软件包下载及安装 **步骤 1** 下载软件包。 [获取参考地址](https://opengauss.obs.cn-south-1.myhuaweicloud.com/1.0.1/DataStudio_win_64.zip) 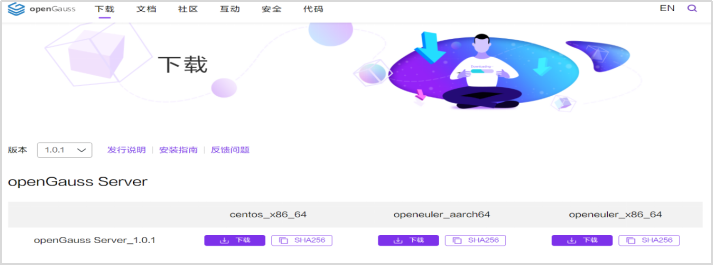 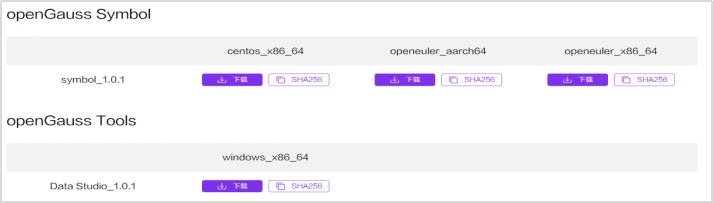 下载后的文件名为:DataStudio_win_64.zip **步骤 2 **解压安装。 将下载的软件包(DataStudio_win_64.zip)解压到自己指定的位置,比如解压至D盘,具体如下: 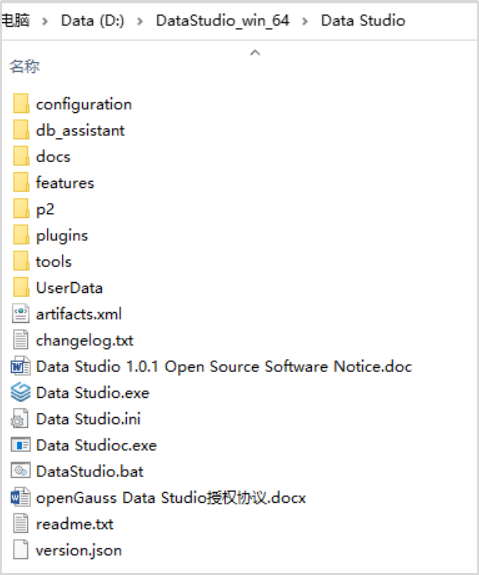 定位并双击Data Studio.exe,启动Data Studio客户端,启动后界面如下:  **步骤 3** 连接数据库。 在Data Studio工具界面上,点击“文件”下的“新建连接”,进入如下设置界面: 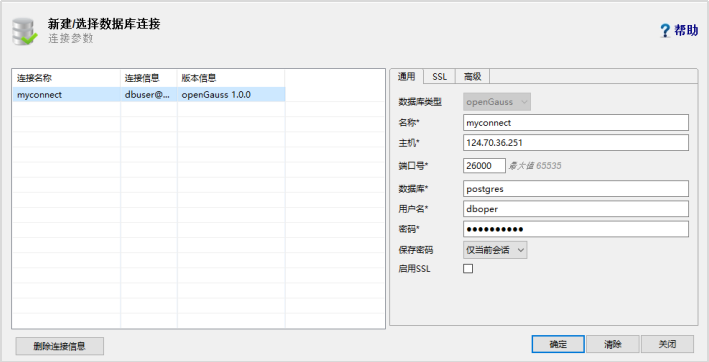 名称:自定义 主机:安有数据库服务器的弹性公网IP 端口:26000 数据库:postgres 用户名:准备连接环境步骤中创建的用户 密码:准备连接环境步骤中创建的用户密码 启用SSL:不启用 设置完成后,点击“确定”按钮进行连接,连接成功后界面如下:  ### 1.3.4 Data Studio用户界面 Data Studio主界面包括: \1. 主菜单:提供使用Data Studio的基本操作; \2. 工具栏:提供常用操作入口; \3. “SQL终端”页签:在该窗口,可以执行SQL语句和函数/过程; \4. “PL/SQL Viewer”页签:显示函数/过程信息; \5. 编辑区域用于进行编辑操作; \6. “调用堆栈”窗格:显示执行栈; \7.“断点“窗格:显示断点信息; \8. “变量”窗格:显示变量及其变量值; \9. “SQL助手”页签:显示“SQL终端”和“PL/SQL Viewer”页签中输入信息的建议或参考; \10. “结果”页签:显示所执行的函数/过程或SQL语句的结果; \11. “消息”页签:显示进程输出。显示标准输入、标准输出和标准错误; \12. “对象浏览器”窗格:显示数据库连接的层级树形结构和用户有权访问的相关数据库对象;除公共模式外,所有默认创建的模式均分组在“系统模式”下,用户模式分组在相应数据库的“用户模式”下; \13. “最小化窗口窗格”:用于打开“调用堆栈”和“变量”窗格。该窗格仅在“调用堆栈”、“变量”窗格中的一个或多个窗格最小化时显示。 \14. 搜索工具栏:用于在“对象浏览器”窗格中搜索对象。 有些项不可见,除非触发特定功能。下图以openGauss界面为例说明: 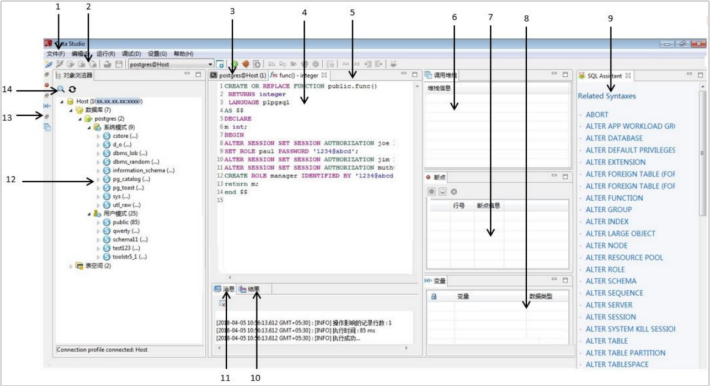 ### 1.3.5 获取工具使用手册 在Data Studio主界面的主菜单上点击帮助下的用户手册,具体如下: 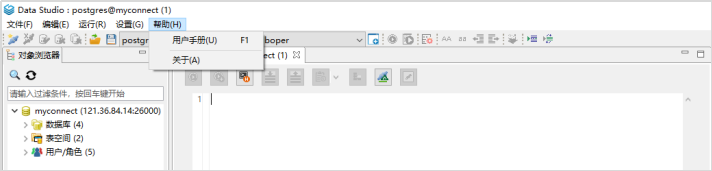 点击后即可得到使用手册,如下:  本实验结束。 # **2** 附录一:Linux操作系统相关命令 Linux中的命令格式为:command [options] [arguments] 中括号表示可选的,即有些命令不需要选项也不需要参数,但有的命令在运行时需要多个选项或参数。 * options(选项):选项是调整命令执行行为的开关,选项的不同决定了命令的显示结果不同。 * agruments(参数):参数是指命令的作用对象。 ## 2.1 vi/vim 文本编辑器,若文件存在则是编辑,若不存在则是创建并编辑文本。 命令语法: vim [参数] 参数说明:可编辑的文件名。 命令示例: * 编辑名为clusterconfig的xml文本: > vim clusterconfig.xml 注: vim编辑器有以下三种模式: * 正常模式:其它模式下按Esc或Ctrl+[进入,左下角显示文件名或为空。 * 插入模式:正常模式下按i键进入,左下角显示--INSERT--。 * 可视模式:正常模式下按v键进入,左下角显示--VISUAL--。 退出命令(正常模式下): * :wq 保存并退出。 * :q! 强制退出并忽略所有更改。 * :e! 放弃所有修改,并打开原有文件。 ## 2.2 cd 显示当前目录的名称,或切换当前的目录(打开指定目录)。 命令语法: cd [参数] 参数说明: * 无参数:切换用户当前目录。 * . :表示当前目录; * .. :表示上一级目录; * ~ :表示home目录; * / :表示根目录。 命令示例: * 切换到usr目录下的bin目录中: > cd /usr/bin * 切换到用户home目录: > cd * 切换到当前目录(cd后面接一个.): > cd . * 切换到当前目录上一级目录(cd后面接两个.): > cd .. * 切换到用户home目录: > cd ~ * 切换到根目录下: > cd / 注:切换目录需要理解绝对路径和相对路径这两个概念。 * 绝对路径:在Linux中,绝对路径是从/(即根目录)开始的,例如 /opt/software、/etc/profile, 如果目录以 / 就是绝对目录。 * 相对路径:是以 . 或 .. 开始的目录。 . 表示用户当前操作所在的位置,而 .. 表示上级目录。例如 ./gs_om 表示当前目录下的文件或者目录。 ## 2.3 mv 文件或目录改名(move (rename) files)或将文件或目录移入其它位置,经常用来备份文件或者目录。 命令语法: mv [选项] 参数1 参数2 常用选项: * -b:若需覆盖文件,则覆盖前先行备份。 参数说明: * 参数1:源文件或目录。 * 参数2:目标文件或目录。 命令示例: * 将文件python重命名为python.bak: > mv python python.bak * 将/physical/backup目录下的所有文件和目录移到/data/dbn1目录下: > mv /physical/backup/* /data/dbn1 ## 2.4 curl 在Linux中curl是一个利用URL规则在命令行下工作的文件传输工具。支持文件的上传和下载,是综合传输工具。 命令语法: curl [选项] [URL] 常用选项: * -A/--user-agent <string>:设置用户代理发送给服务器; * -C/--continue-at <offset>:断点续转; * -D/--dump-header <file>:把header信息写入到该文件中; * -e/--referer:来源网址; * -o/--output:把输出写到该文件中; * -O/--remote-name:把输出写到该文件中,保留远程文件的文件名; * -s/--silent:静默模式。不输出任何东西; * -T/--upload-file <file>:上传文件; * -u/--user <user[:password]>:设置服务器的用户和密码; * -x/--proxy <host[:port]>:在给定的端口上使用HTTP代理; * -#/--progress-bar:进度条显示当前的传送状态。 参数说明: * URL:指定的文件传输URL地址。 命令示例: * 将url(https://mirrors.huaweicloud.com/repository/conf/CentOS-7-anon.repo)的内容保存到/etc/yum.repos.d/CentOS-Base.repo文件中。 > curl -o /etc/yum.repos.d/CentOS-Base.repo https://mirrors.huaweicloud.com/repository/conf/CentOS-7-anon.repo * 如果在传输过程中掉线,可以使用-C的方式进行续传。 > curl -C -O https://mirrors.huaweicloud.com/repository/conf/CentOS-7-anon.repo ## 2.5 yum Shell 前端软件包管理器。基于 RPM 包管理,能够从指定的服务器自动下载 RPM 包并且安装,可以自动处理依赖性关系,并且一次安装所有依赖的软体包,无须繁琐地一次次下载和安装。 命令语法: yum [options] [command] [package ...] 常用选项: * -h:查看帮助; * -y:当安装过程提示选择全部为 "yes"; * -q:不显示安装的过程。 参数说明: * command:要进行的操作。 * package:安装的包名。 命令示例: * 列出所有可更新的软件清单命令: > yum check-update * 更新所有软件命令: > yum update * 列出所有可安裝的软件清单命令: > yum list * 安装指定的软件: > yum install -y libaio-devel flex bison ncurses-devel glibc.devel patch lsb_release wget python3 ## 2.6 wget wget是Linux下下载文件的最常用命令。wget支持HTTP,HTTPS和FTP协议,支持自动下载,即可以在用户退出系统后在后台执行,直到下载结束。 命令语法: wget [选项] [URL] 常用选项: * -c:接着下载没下载完的文件; * -b:启动后转入后台执行; * -P:指定下载目录; * -O:变更下载文件名; * --ftp-user --ftp-password:使用FTP用户认证下载。 参数说明: * 指定的文件下载URL地址。 命令示例: * 下载openGauss数据库安装文件到当前文件夹: > wget https://opengauss.obs.cn-south-1.myhuaweicloud.com/1.0.0/x86/openGauss-1.0.0-CentOS-64bit.tar.gz * 使用wget断点续传: > wget –c https://opengauss.obs.cn-south-1.myhuaweicloud.com/1.0.0/x86/openGauss-1.0.0-CentOS-64bit.tar.gz ## 2.7 ln 为某一个文件在另外一个位置建立一个同步的链接(软硬链接,不带选项为硬链接)。 当需要在不同的目录,用到相同的文件时,就不需要在每一个需要要的目录下都放一个必须相同的文件,我们只要在某个固定的目录,放上该文件,然后在 其它的目录下用ln命令链接(link)它就可以,不必重复的占用磁盘空间。 命令语法: ln [选项] 参数1 参数2 常用选项: * -b --删除,覆盖以前建立的链接; * -d --允许超级用户制作目录的硬链接; * -s --软链接(符号链接)。 参数说明: * 参数1:源文件或目录。 * 参数2:被链接的文件或目录。 命令示例: * 为python3文件创建软链接/usr/bin/python,如果python3丢失,/usr/bin/python将失效: > ln -s python3 /usr/bin/python * 为python3创建硬链接/usr/bin/python,python3与/usr/bin/python的各项属性相同: > ln python3 /usr/bin/python ## 2.8 mkdir 创建指定的名称的目录,要求创建目录的用户在当前目录中具有写权限,并且指定的目录名不能是当前目录中已有的目录。 命令语法: mkdir [选项] [参数] 常用选项: * -p --可以是一个路径名称。此时若路径中的某些目录尚不存在,加上此选项后,系统将自动建立好那些尚不存在的目录,即一次可以建立多个目录(递归); * -v --每次创建新目录都显示信息; * -m --设定权限<模式> (类似chmod),而不是rwxrwxrwx减umask。 参数说明: * 需要创建的目录。 命令示例: * 创建一个空目录: > mkdir test * 递归创建多个目录: > mkdir -p /opt/software/openGauss * 创建权限为777的目录(目录的权限为rwxrwxrwx): > mkdir –m 777 test ## 2.9 chmod命令 更改文件权限。 命令语法: chmod [选项] <mode> <file...> 常用选项: * -R, --以递归的方式对目前目录下的所有文件与子目录进行相同的权限变更。 参数说明: * mode:权限设定字串,详细格式如下 : [ugoa...][[+-=][rwxX]...][,...], 其中,[ugoa...]:u 表示该档案的拥有者,g 表示与该档案的拥有者属于同一个群体(group)者,o 表示其他以外的人,a 表示所有(包含上面三者);[+-=]:+ 表示增加权限,- 表示取消权限,= 表示唯一设定权限;[rwxX]:r 表示可读取,w 表示可写入,x 表示可执行,X表示只有当该档案是个子目录或者该档案已经被设定过为可执行。 * file:文件列表(单个或者多个文件、文件夹)。 命令示例: * 设置所有用户可读取文件 cluterconfig.xml: > chmod ugo+r cluterconfig.xml 或 > chmod a+r cluterconfig.xml * 设置当前目录下的所有档案与子目录皆设为任何人可读写: > chmod -R a+rw * 数字权限使用格式: * 这种使用方式中,规定数字4、2和1表示读、写、执行权限,即r=4,w=2,x=1。 * 例:rwx = 7(4+2+1);rw = 6(4+2);r-x = 5 (4+0+1);r-- = 4(4+0+0);--x = 1(0+0+1); 每个文件都可以针对三个粒度,设置不同的rwx(读写执行)权限。即我们可以用用三个8进制数字分别表示 拥有者 、群组 、其它组( u、 g 、o)的权限详情,并用chmod直接加三个8进制数字的方式直接改变文件权限。语法格式为 : chmod <abc> file... 其中,a,b,c各为一个数字,分别代表User、Group、及Other的权限,相当于简化版的chmod u=权限,g=权限,o=权限 file...,而此处的权限将用8进制的数字来表示User、Group、及Other的读、写、执行权限。 命令示例: * 赋予cluterconfig.xml文件可读可写可执行权限(所有权限): > chmod 777 cluterconfig.xml * 赋予/opt/software/openGauss目录下所有文件及其子目录 用户所有权限组可读可执行权限,其他用户可读可执行权限: > chmod R 755 /opt/software/openGauss ## 2.10 chown 利用 chown 将指定文件的拥有者改为指定的用户或组,用户可以是用户名或者用户ID;组可以是组名或者组ID;文件是以空格分开的要改变权限的文件列表,支持通配符。只有系统管理者(root)才有这样的权限。使用权限 : **root**。 命令语法: chown [选项] user[:group] file... 常用选项: * -c : 显示更改的部分的信息; * -f : 忽略错误信息; * -R : 处理指定目录以及其子目录下的所有文件。 参数说明 * user : 新的文件拥有者的使用者 ID。 * group : 新的文件拥有者的使用者组(group)。 * flie:文件。 命令示例: * 将文件 file1.txt 的拥有者设为omm,群体的使用者dbgrp: > chown omm:dbgrp /opt/software/openGauss/clusterconfig.xml * 将目前目录下的所有文件与子目录的拥有者皆设为omm,群体的使用者dbgrp: > chown -R omm:dbgrp * ## 2.11 ls 列出文件和目录的内容。 命令语法: ls [选项] [参数] 常用选项: * -l --以长格式显示,列出文件的详细信息,如创建者,创建时间,文件的读写权限列表等等; * -a --列出文件下所有的文件,包括以"."和".."开头的隐藏文件 (Linux下文件隐藏文件是以 .开头的,如果存在 .. 代表存在着父目录); * -d --列出目录本身而非目录内的文件,通常要与-l一起使用; * -R --同时列出所有子目录层,与-l相似,只是不显示出文件的所有者,相当于编程中的“递归”实现; * -t --按照时间进行文件的排序,Time(时间); * -s --在每个文件的后面打印出文件的大小,size(大小); * -S --以文件的大小进行排序。 参数说明: * 目录或文件。 命令示例: * 以长格式列出当前目录中的文件及目录: > ls -l ## 2.12 cp 复制文件或者目录。 命令语法: cp [选项] 参数1 参数2 常用选项: * -f --如果目标文件无法打开则将其移除并重试(当 -n 选项存在时则不需再选此项); * -n --不要覆盖已存在的文件(使前面的 -i 选项失效); * -I --覆盖前询问(使前面的 -n 选项失效); * -p --保持指定的属性(默认:模式,所有权,时间戳),如果可能保持附加属性:环境、链接、xattr 等; * -R,-r --复制目录及目录内的所有项目。 参数说明: * 参数1:源文件。 * 参数2:目标文件。 命令示例: * 将home目录中的abc文件复制到opt目录下: > cp /home/abc /opt 注:目标文件存在时,会询问是否覆盖。这是因为cp是cp -i的别名。目标文件存在时,即使加了-f标志,也还会询问是否覆盖。 ## 2.13 rm 删除一个目录中的一个或多个文件或目录,它也可以将某个目录及其下的所有文件及子目录均删除。对于链接文件,只是删除了链接,原有文件均保持不变。 rm是一个危险的命令,使用的时候要特别当心,否则整个系统就会毁在这个命令(比如在/(根目录)下执行rm * rf)。所以,我们在执行rm之前最好先确认一下在哪个目录,到底要删除什么东西,操作时保持高度清醒的头脑。 命令语法: rm [选项] 文件 常用选项: * -f --忽略不存在的文件,从不给出提示; * -r --指示rm将参数中列出的全部目录和子目录均递归地删除。 参数说明: * 需要删除的文件或目录。 命令示例: * 删除文件: > rm qwe 注:输入rm qwe命令后,系统会询问是否删除,输入y后就会删除文件,不想删除文件则输入n。 * 强制删除某个文件: > rm-rf clusterconfig.log ## 2.14 cat 连接文件并在标准输出上输出。这个命令常用来显示文件内容,或者将几个文件连接起来显示,或者从标准输入读取内容并显示,它常与重定向符号配合使用。 命令语法: cat [选项] [参数] 常用选项: * -E --在每行结束显示$; * -n –由1开始对给所有输出行编号; * -b 或 --number-nonblank:和 -n 相似,只不过对于空白行不编号; * -v --使用 ^ 和 M- 符号,除了 LFD 和 TAB 之外。 参数说明: * 可操作的文件名。 命令示例: * 显示testfile文件的内容: > cat textfile * 把 textfile1 和 textfile2 的文档内容加上行号(空白行不加)之后将内容追加到 textfile3 文档里: > cat -b textfile1 textfile2 >> textfile3 * 向/etc/profile中追加内容(输入EOF表示结束追加): > cat >>/etc/profile<<EOF > > \>export LD_LIBRARY_PATH=$packagePath/script/gspylib/clib:$LD_LIBRARY_PATH > > \>EOF 注: * EOF是end of file的缩写,表示"文字流"(stream)的结尾。"文字流"可以是文件(file),也可以是标准输入(stdin)。在Linux系统之中,EOF是当系统读取到文件结尾,所返回的一个信号值(也就是-1)。 ## 2.15 touch 用于修改文件或者目录的时间属性,包括存取时间和更改时间。若文件不存在,系统会建立一个新的文件。 命令语法: touch [选项] [参数] 常用选项: * -a 改变档案的读取时间记录; * -m 改变档案的修改时间记录; * -c 假如目的档案不存在,不会建立新的档案; * -d 使用指定的日期时间,而非现在的时间。 参数说明: * 可操作的文件名。 命令示例: * 修改文件"output.txt "的时间属性为当前系统时间,如果指定的文件不存在,则将创建一个新的空白文件: > touch /home/omm/openGauss/output.txt * 把 textfile的文档时间指定为2020年12月27日15时44分: > touch -d "2020-12-27 15:44" textfile # **3** 附录二:openGauss数据库基本操作 ## 3.1 查看数据库对象 * 查看帮助信息: > postgres=# \? * 切换数据库: > *postgres*=# \c dbname * 列举数据库: 使用\l元命令查看数据库系统的数据库列表。 > postgres=# \l 使用如下命令通过系统表pg_database查询数据库列表。 *postgres*=# SELECT datname FROM pg_database; * 列举表: > postgres=# \dt * 列举所有表、视图和索引: > postgres=# \d+ 使用gsql的\d+命令查询表的属性。 > *postgres*=# \d+ tablename * 查看表结构: > *postgres*=# \d tablename * 列举schema: > postgres=# \dn * 查看索引: > postgres=# \di * 查询表空间: 使用gsql程序的元命令查询表空间。 > postgres=# \db 检查pg_tablespace系统表。如下命令可查到系统和用户定义的全部表空间。 > *postgres*=# SELECT spcname FROM pg_tablespace; * 查看数据库用户列表: > *postgres*=# SELECT * FROM pg_user; * 要查看用户属性: > *postgres*=# SELECT * FROM pg_authid; * 查看所有角色: > *postgres*=# SELECT * FROM PG_ROLES; ## 3.2 其他操作 * 查看openGauss支持的所有SQL语句。 > postgres=#\h * 切换数据库: > *postgres*=# \c dbname * 切换用户: > *postgres*=# \c – username * 退出数据库: > postgres=# \q
上一篇:
01Kafka安装
下一篇:
02-Flink-WordCount编程
文档导航

 浙ICP备案2024056857号
浙ICP备案2024056857号
 浙公网安备33020502001085号
浙公网安备33020502001085号