大数据学习
bigdata learning
Toggle navigation
大数据学习
主页
openGauss数据库
Flume
MongoDB
Hadoop
数据库实验
Kafka
Zookeeper
Hbase
Manual
Spark
Neo4j
InfluxDB
RabbitMQ
Flink
About Me
归档
标签
05-Spark-Scala编程
无
2023-04-24 13:04:29
83
0
0
bigdata
## 独立应用程序(Self-Contained Applications) 接着我们通过一个简单的应用程序 SimpleApp 来演示如何通过 Spark API 编写一个独立应用程序。使用 Scala 编写的程序需要使用 sbt 进行编译打包,相应的,Java 程序使用 Maven 编译打包,而 Python 程序通过 spark-submit 直接提交。 ### 应用程序代码 在终端中执行如下命令创建一个文件夹 sparkapp 作为应用程序根目录: ```shell $ cd ~ # 进入用户主文件夹 $ mkdir ./sparkapp # 创建应用程序根目录 $ mkdir -p ./sparkapp/src/main/scala # 创建所需的文件夹结构 ``` 在 ./sparkapp/src/main/scala 下建立一个名为 SimpleApp.scala 的文件(`vim ./sparkapp/src/main/scala/SimpleApp.scala`),添加代码如下: ```scala 1. /* SimpleApp.scala */ 2. import org.apache.spark.SparkContext 3. import org.apache.spark.SparkContext._ 4. import org.apache.spark.SparkConf 5. 6. object SimpleApp { 7. def main(args: Array[String]) { 8. val logFile = "file:///usr/local/spark/README.md" // Should be some file on your system 9. val conf = new SparkConf().setAppName("Simple Application") 10. val sc = new SparkContext(conf) 11. val logData = sc.textFile(logFile, 2).cache() 12. val numAs = logData.filter(line => line.contains("a")).count() 13. val numBs = logData.filter(line => line.contains("b")).count() 14. println("Lines with a: %s, Lines with b: %s".format(numAs, numBs)) 15. } 16. } ``` 该程序计算 /usr/local/spark/README 文件中包含 “a” 的行数 和包含 “b” 的行数。代码第 8 行的/usr/local/spark 为 Spark 的安装目录,如果不是该目录请自行修改。不同于 Spark shell,独立应用程序需要通过 `val sc = new SparkContext(conf)` 初始化 SparkContext,SparkContext 的参数 SparkConf 包含了应用程序的信息。该程序依赖 Spark API,因此我们需要通过 sbt 进行编译打包。在 ./sparkapp 中新建文件 simple.sbt(`vim ./sparkapp/simple.sbt`),添加内容如下,声明该独立应用程序的信息以及与 Spark 的依赖关系: name := "Simple Project" version := "1.0" scalaVersion := "2.10.5" libraryDependencies += "org.apache.spark" %% "spark-core" % "1.6.0" 文件 simple.sbt 需要指明 Spark 和 Scala 的版本。启动 Spark shell 的过程中,当输出到 Spark 的符号图形时,可以看到相关的版本信息。 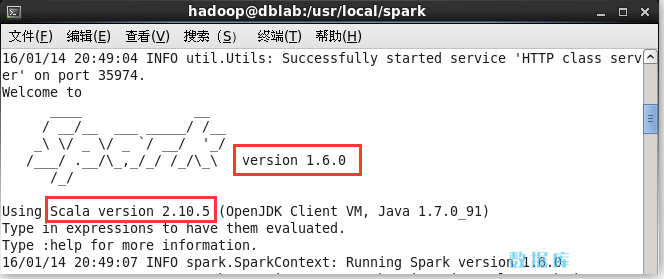 ### 安装 sbt Spark 中没有自带 sbt,需要[手动安装 sbt](http://www.scala-sbt.org/0.13/docs/zh-cn/Manual- Installation.html),我们选择安装在 /usr/local/sbt 中: ```shell $ sudo mkdir /usr/local/sbt $ sudo chown -R hadoop /usr/local/sbt # 此处的 hadoop 为你的用户名 $ cd /usr/local/sbt ``` 经笔者测试,按官网教程安装 sbt 0.13.9 后,使用时可能存在网络问题,无法下载依赖包,导致 sbt 无法正常使用,需要进行一定的修改。为方便,请使用笔者修改后的版本,下载地址:<http://pan.baidu.com/s/1eRyFddw>。 下载后,执行如下命令拷贝至 /usr/local/sbt 中: ```shell $ cp ~/下载/sbt-launch.jar . ``` 接着在 /usr/local/sbt 中创建 sbt 脚本(`vim ./sbt`),添加如下内容: ```shell $ #!/bin/bash $ SBT_OPTS="-Xms512M -Xmx1536M -Xss1M -XX:+CMSClassUnloadingEnabled -XX:MaxPermSize=256M" $ java $SBT_OPTS -jar `dirname $0`/sbt-launch.jar "$@" ``` 保存后,为 ./sbt 脚本增加可执行权限: ```shell $ chmod u+x ./sbt ``` 最后检验 sbt 是否可用(首次运行会处于 “Getting org.scala-sbt sbt 0.13.9 …” 的下载状态,请耐心等待。笔者等待了 7 分钟才出现第一条下载提示): ```shell $ ./sbt sbt-version ``` 下载过程中可能会类似 “Server access Error: java.security.ProviderException: java.security.KeyException url=https://jcenter.bintray.com/org/scala-sbt/precompiled-2_9_3/0.13.9/precompiled-2_9_3-0.13.9.jar” 的错误,可以忽略。可再执行一次`./sbt sbt-version`,只要能得到如下图的版本信息就没问题:  如果由于网络问题无法下载依赖,导致 sbt 无法正确运行的话,可以下载笔者提供的离线依赖包 sbt-0.13.9-repo.tar.gz 到本地中(依赖包的本地位置为 ~/.sbt 和 ~/.ivy2,检查依赖关系时,首先检查本地,本地未找到,再从网络中下载),下载地址:http://pan.baidu.com/s/1sjTQ8yD>。下载后,执行如下命令解压依赖包: ```shell $ tar -zxf ~/下载/sbt-0.13.9-local-repo.tar.gz ~ ``` 通过这个方式,一般可以解决依赖包缺失的问题(读者提供的依赖包仅适合于 Spark 1.6 版本,不同版本依赖关系不一样)。 如果对 sbt 存在的网络问题以及如何解决感兴趣,请点击下方查看。
上一篇:
05-Neo4j-RETURN命令
下一篇:
05-Zookeeper客户端基础命令
文档导航

 浙ICP备案2024056857号
浙ICP备案2024056857号
 浙公网安备33020502001085号
浙公网安备33020502001085号