大数据学习
bigdata learning
Toggle navigation
大数据学习
主页
openGauss数据库
Flume
MongoDB
Hadoop
数据库实验
Kafka
Zookeeper
Hbase
Manual
Spark
Neo4j
InfluxDB
RabbitMQ
Flink
About Me
归档
标签
06-Kafka消费者组示例
Kafka
Java
2022-12-05 23:06:00
38
0
0
bigdata
Kafka
Java
消费群是多线程或多机器的 Apache Kafka 主题。 # 消费者群体 * 消费者可以使用相同的 group.id 加入群组 * 一个组的最大并行度是组中的消费者数量←不是分区。 * Kafka 将主题的分区分配给组中的使用者,以便每个分区仅由组中的一个使用者使用。 * Kafka 保证消息只能被组中的一个消费者读取。 * 消费者可以按照消息存储在日志中的顺序查看消息。 ## 重新平衡消费者 添加更多进程 / 线程将导致 Kafka 重新平衡。 如果任何消费者或代理无法向 ZooKeeper 发送心跳,则可以通过 Kafka 集群重新配置。 在此重新平衡期间,Kafka 将分配可用分区到可用线程,可能将分区移动到另一个进程。 ```java import java.util.Properties; import java.util.Arrays; import org.apache.kafka.clients.consumer.KafkaConsumer; import org.apache.kafka.clients.consumer.ConsumerRecords; import org.apache.kafka.clients.consumer.ConsumerRecord; public class ConsumerGroup { public static void main(String[] args) throws Exception { if(args.length < 2){ System.out.println("Usage: consumer <topic> <groupname>"); return; } String topic = args[0].toString(); String group = args[1].toString(); Properties props = new Properties(); props.put("bootstrap.servers", "localhost:9092"); props.put("group.id", group); props.put("enable.auto.commit", "true"); props.put("auto.commit.interval.ms", "1000"); props.put("session.timeout.ms", "30000"); props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(props); consumer.subscribe(Arrays.asList(topic)); System.out.println("Subscribed to topic " + topic); int i = 0; while (true) { ConsumerRecords<String, String> records = consumer.poll(100); for (ConsumerRecord<String, String> record : records) System.out.printf("offset = %d, key = %s, value = %s\n", record.offset(), record.key(), record.value()); } } } ``` ## 编译 ```bash nbu@ecs:~/bigdata/kafka/kafka-demo$ javac -cp "/usr/local/kafka/libs/*":. ConsumerGroup.java ``` > 若在CLASSPATH中指定了`/usr/local/kafka/libs/*`,则不需要`-cp "/usr/local/kafka/libs/*":.`来指定kafka库文件位置 ## 执行 ```bash nbu@ecs:~$ cd bigdata/kafka/kafka-demo/ nbu@ecs:~/bigdata/kafka/kafka-demo$ java ConsumerGroup nbu my-group ``` 在这里,我们为两个消费者创建了一个示例组名称为 my-group 。 同样,可以在组中创建组和消费者数量。 ## 输入 打开生产者 CLI 并发送一些消息 ``` Test consumer group 01 Test consumer group 02 ``` ## 输出结果  ##用SimpleProducer作输入 另开启一个终端运行上一节的SimpleProducer程序 ```bash nbu@ecs:~/bigdata/kafka/kafka-demo$ java SimpleProducer nbu ``` 可在消费者端看到如下结果 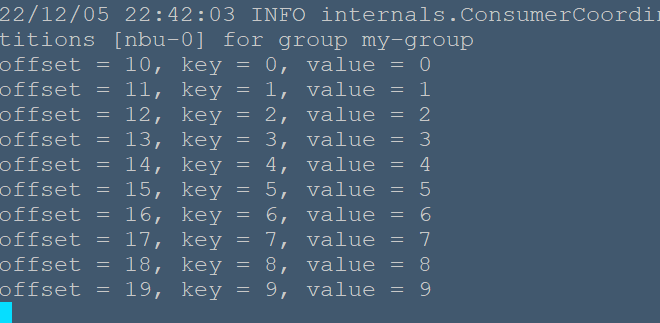 Consumer 客户端 API 主配置设置的配置设置如下所示: <table><tbody><tr><td width:100px="">1</td><td>引导代理列表。</td></tr><tr><td width:="" 100px="">2</td><td>group.id<br>将单个消费者分配给组。</td></tr><tr><td width:="" 100px="">3</td><td>enable.auto.commit<br>如果值为 true,则为偏移启用自动落实,否则不提交。</td></tr><tr><td width:="" 100px="">4</td><td>auto.commit.interval.ms<br>返回更新的消耗偏移量写入 ZooKeeper 的频率。</td></tr><tr><td width:="" 100px="">5</td><td>session.timeout.ms<br>表示 Kafka 在放弃和继续消费消息之前等待 ZooKeeper 响应请求 (读取或写入) 多少毫秒。</td></tr></tbody></table>
上一篇:
06-InfluxDB数据查询语法
下一篇:
06-MongoDB 查询文档
文档导航

 浙ICP备案2024056857号
浙ICP备案2024056857号
 浙公网安备33020502001085号
浙公网安备33020502001085号