大数据学习
bigdata learning
Toggle navigation
大数据学习
主页
openGauss数据库
Flume
MongoDB
Hadoop
数据库实验
Kafka
Zookeeper
Hbase
Manual
Spark
Neo4j
InfluxDB
RabbitMQ
Flink
About Me
归档
标签
04-Hive数据库创建-删除
无
2022-11-07 15:02:40
20
0
0
bigdata
Hive 是一种数据库技术,可以定义数据库和表来分析结构化数据。主题结构化数据分析是以表方式存储数据,并通过查询来分析。本章介绍如何创建 Hive 数据库。配置单元包含一个名为 default 默认的数据库。 # CREATE DATABASE 语句 创建数据库是用来创建数据库在 Hive 中语句。在 Hive 数据库是一个命名空间或表的集合。此语法声明如下: ``` CREATE DATABASE|SCHEMA [IF NOT EXISTS] <database name> ``` 在这里,IF NOT EXISTS 是一个可选子句,通知用户已经存在相同名称的数据库。可以使用 SCHEMA 在 DATABASE 的这个命令。下面的查询执行创建一个名为 nbubd 数据库: ``` hive> CREATE DATABASE [IF NOT EXISTS] nbudb; ``` 或 ``` hive> CREATE SCHEMA nbudb; ``` 下面的查询用于验证数据库列表: ``` hive> SHOW DATABASES; OK default nbudb Time taken: 0.013 seconds, Fetched: 2 row(s) ``` ## JDBC 程序 在 JDBC 程序来创建数据库如下。 ``` import java.sql.SQLException; import java.sql.Connection; import java.sql.ResultSet; import java.sql.Statement; import java.sql.DriverManager; public class HiveCreateDB { // private static String driverName = "org.apache.hadoop.hive.jdbc.HiveDriver"; private static String driverName = "org.apache.hive.jdbc.HiveDriver"; public static void main(String[] args) throws SQLException, ClassNotFoundException { // Register driver and create driver instance Class.forName(driverName); // get connection // Connection con = DriverManager.getConnection("jdbc:hive://localhost:10000/default", "", ""); Connection con = DriverManager.getConnection("jdbc:hive2://localhost:10000/default", "", ""); Statement stmt = con.createStatement(); stmt.execute("CREATE DATABASE nbudb_java"); System.out.println("Database nbudb_java created successfully."); con.close(); } } ``` > 必须把`/usr/local/hive/lib/` 写入$CLASSPATH中,否则会出现找不到jdbc驱动的情况 如:java.lang.ClassNotFoundException: org.apache.Hive.jdbc.HiveDriver 此外,Class.forName 是区分大小写,注意org.apache.hive.jdbc.HiveDriver 的大小写 保存程序在一个名为 HiveCreateDB.java 文件。下面的命令用于编译和执行这个程序。 ``` $ javac HiveCreateDB.java $ java HiveCreateDB ``` ## 输出: ``` Database userdb created successfully. ``` 可在hive中查看到用java程序创建的数据库 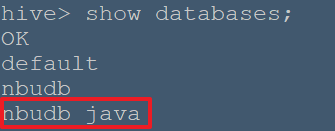 >问题1 需要开启 hiveserver2 >```bash >nbu@ecs:~$ /usr/local/hive/bin/hive --service hiveserver2 & >``` >问题2 org.apache.hadoop.hive.ql.exec.DDLTask. MetaException(message:Got exception: org.apache.hadoop.security.AccessControlException Permission denied: user=anonymous, access=WRITE, inode="/user/hive/warehouse/nbudb_java.db":nbu:supergroup:drwxr-xr-x >说明在hdfs中文件夹`/user/hive/warehouse`没有写权限,可尝试改变文件夹权限 >```bash >nbu@ecs:~/bigdata/hive$ hdfs dfs -chmod 777 /user/hive/warehouse/ >``` Hive 删除数据库,模式和数据库的使用是一样的。 # DROP DATABASE 语句 DROP DATABASE 是删除所有的表并删除数据库的语句。它的语法如下: ``` DROP DATABASE StatementDROP (DATABASE|SCHEMA) [IF EXISTS] database_name [RESTRICT|CASCADE]; ``` 下面的查询用于删除数据库。假设要删除的数据库名称为 userdb。 ``` hive> DROP DATABASE IF EXISTS nbudb; OK Time taken: 0.135 seconds ``` 以下是使用 CASCADE 查询删除数据库。这意味着要全部删除相应的表在删除数据库之前。 ``` hive> DROP DATABASE IF EXISTS nbudb CASCADE; ``` 以下使用 SCHEMA 查询删除数据库。 ``` hive> DROP SCHEMA nbudb; ``` ## JDBC Program 在 JDBC 程序来删除数据库如下。 ``` import java.sql.SQLException; import java.sql.Connection; import java.sql.ResultSet; import java.sql.Statement; import java.sql.DriverManager; public class HiveDropDB { // private static String driverName = "org.apache.hadoop.hive.jdbc.HiveDriver"; private static String driverName = "org.apache.hive.jdbc.HiveDriver"; public static void main(String[] args) throws SQLException, ClassNotFoundException { // Register driver and create driver instance Class.forName(driverName); // get connection Connection con = DriverManager.getConnection("jdbc:hive2://localhost:10000/default", "", ""); Statement stmt = con.createStatement(); stmt.execute("DROP DATABASE nbudb_java"); System.out.println("Drop nbudb_java database successful."); con.close(); } } ``` 将该程序保存在一个名为 HiveDropDB.java 文件。下面给出的是编译和执行这个程序的命令。 ``` $ javac HiveDropDb.java $ java HiveDropDb ``` ## Output: ``` Drop userdb database successful. ``` 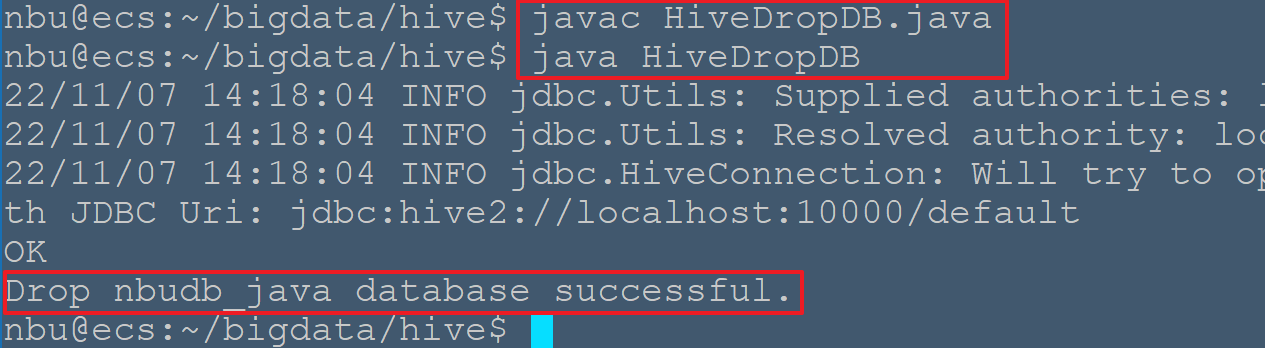
上一篇:
04-Hadoop-HDFS-JavaApi-Maven
下一篇:
04-InfluxDB查询数据
文档导航

 浙ICP备案2024056857号
浙ICP备案2024056857号
 浙公网安备33020502001085号
浙公网安备33020502001085号