大数据学习
bigdata learning
Toggle navigation
大数据学习
主页
openGauss数据库
Flume
MongoDB
Hadoop
数据库实验
Kafka
Zookeeper
Hbase
Manual
Spark
Neo4j
InfluxDB
RabbitMQ
Flink
About Me
归档
标签
JDK安装
无
2022-10-29 23:31:24
279
0
0
bigdata
## 安装JDK 下面有三种安装 JDK 的方式,可以任选一种。推荐直接使用第 1 种安装方式。 1. 第 1 种安装 JDK 方式(手动安装,推荐采用本方式) 需要按照下面步骤来自己手动安装 JDK1.8。 我们已经把 JDK1.8 的安装包 jdk-8u162-linux-x64.tar.gz 放在了百度云盘,[可以点击这里到百度云盘下载 JDK1.8 安装包](https://pan.baidu.com/s/1mUR3M2U_lbdBzyV_p85eSA)(提取码:99bg)。请把压缩格式的文件 jdk-8u162-linux-x64.tar.gz 下载到本地电脑,假设保存在“/home/linziyu/Downloads/”目录下。 在 Linux 命令行界面中,执行如下 Shell 命令(注意:当前登录用户名是 hadoop): ```shell cd /usr/lib sudo mkdir jvm #创建/usr/lib/jvm目录用来存放JDK文件 cd ~ #进入hadoop用户的主目录 cd Downloads #注意区分大小写字母,刚才已经通过FTP软件把JDK安装包jdk-8u162-linux-x64.tar.gz上传到该目录下 sudo tar -zxvf ./jdk-8u162-linux-x64.tar.gz -C /usr/lib/jvm #把JDK文件解压到/usr/lib/jvm目录下 ``` 上面使用了解压缩命令 tar,如果对 Linux 命令不熟悉,可以参考[常用的 Linux 命令用法](http://dblab.xmu.edu.cn/blog/1624-2/)。 JDK 文件解压缩以后,可以执行如下命令到/usr/lib/jvm 目录查看一下: ```shell cd /usr/lib/jvm ls ``` 可以看到,在/usr/lib/jvm 目录下有个 jdk1.8.0_162 目录。 下面继续执行如下命令,设置环境变量: ```shell cd ~ vim ~/.bashrc ``` 上面命令使用 vim 编辑器([查看 vim 编辑器使用方法](http://dblab.xmu.edu.cn/blog/1607-2/))打开了 hadoop 这个用户的环境变量配置文件,请在这个文件的开头位置,添加如下几行内容: ``` export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_162 export JRE_HOME=${JAVA_HOME}/jre export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib export PATH=${JAVA_HOME}/bin:$PATH ``` 保存.bashrc 文件并退出 vim 编辑器。然后,继续执行如下命令让.bashrc 文件的配置立即生效: ```shell source ~/.bashrc ``` 这时,可以使用如下命令查看是否安装成功: ```shell java -version ``` 如果能够在屏幕上返回如下信息,则说明安装成功: ``` hadoop@ubuntu:~$ java -version java version "1.8.0_162" Java(TM) SE Runtime Environment (build 1.8.0_162-b12) Java HotSpot(TM) 64-Bit Server VM (build 25.162-b12, mixed mode) ``` 2. 第 2 种安装 JDK 方式: ```shell sudo apt-get install openjdk-7-jre openjdk-7-jdk ``` 安装好 OpenJDK 后,需要找到相应的安装路径,这个路径是用于配置 JAVA_HOME 环境变量的。执行如下命令: ```shell dpkg -L openjdk-7-jdk | grep '/bin/javac' ``` 该命令会输出一个路径,除去路径末尾的 “/bin/javac”,剩下的就是正确的路径了。如输出路径为 /usr/lib/jvm/java-7-openjdk-amd64/bin/javac,则我们需要的路径为 /usr/lib/jvm/java-7-openjdk-amd64。 接着需要配置一下 JAVA_HOME 环境变量,为方便,我们在 ~/.bashrc 中进行设置(扩展阅读: [设置 Linux 环境变量的方法和区别](http://dblab.xmu.edu.cn/blog/linux-environment-variable/)): ```shell vim ~/.bashrc ``` 在文件最前面添加如下单独一行(注意 = 号前后不能有空格),将“JDK 安装路径”改为上述命令得到的路径,并保存: ```shell export JAVA_HOME=JDK安装路径 ``` 如下图所示(该文件原本可能不存在,内容为空,这不影响): 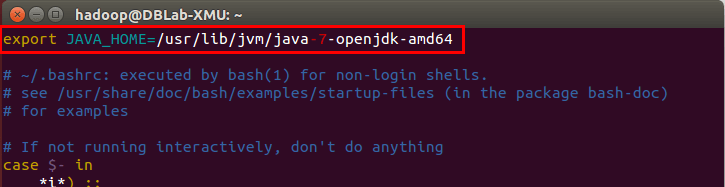 接着还需要让该环境变量生效,执行如下代码: ``` source ~/.bashrc # 使变量设置生效 ``` 设置好后我们来检验一下是否设置正确: ```shell echo $JAVA_HOME # 检验变量值 java -version $JAVA_HOME/bin/java -version # 与直接执行 java -version 一样 ``` 如果设置正确的话,`$JAVA_HOME/bin/java -version` 会输出 java 的版本信息,且和 `java -version` 的输出结果一样,如下图所示: 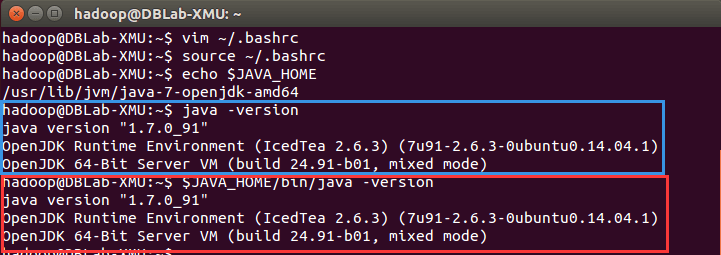 这样,Hadoop 所需的 Java 运行环境就安装好了。 3. 第三种安装 JDK 方式 根据大量电脑安装 Java 环境的情况我们发现,部分电脑按照上述的第一种安装方式会出现安装失败的情况,这时,可以采用这里介绍的另外一种安装方式,命令如下: ```shell sudo apt-get install default-jre default-jdk ``` 上述安装过程需要访问网络下载相关文件,请保持联网状态。安装结束以后,需要配置 JAVA_HOME 环境变量,请在 Linux 终端中输入下面命令打开当前登录用户的环境变量配置文件.bashrc: ```shell vim ~/.bashrc ``` 在文件最前面添加如下单独一行(注意,等号“=”前后不能有空格),然后保存退出: ``` export JAVA_HOME=/usr/lib/jvm/default-java ``` 接下来,要让环境变量立即生效,请执行如下代码: ```shell source ~/.bashrc # 使变量设置生效 ``` 执行上述命令后,可以检验一下是否设置正确: ```shell echo $JAVA_HOME # 检验变量值 java -version $JAVA_HOME/bin/java -version # 与直接执行java -version一样 ``` 至此,就成功安装了 Java 环境。下面就可以进入 Hadoop 的安装。
上一篇:
6 RPC调用
下一篇:
Javac jar打包
文档导航

 浙ICP备案2024056857号
浙ICP备案2024056857号
 浙公网安备33020502001085号
浙公网安备33020502001085号