大数据学习
bigdata learning
Toggle navigation
大数据学习
主页
openGauss数据库
Flume
MongoDB
Hadoop
数据库实验
Kafka
Zookeeper
Hbase
Manual
Spark
Neo4j
InfluxDB
RabbitMQ
Flink
About Me
归档
标签
08-Flume案例-复制和多路复用
Flume
2022-09-27 17:20:31
65
0
0
bigdata
Flume
# Flume案例-复制和多路复用 ## 1)案例需求: 使用 Flume-1 监控文件变动, Flume-1 将变动内容传递给 Flume-2, Flume-2 负责存储到 HDFS。同时 Flume-1 将变动内容传递给 Flume-3,Flume-3 负责输出到 Local FileSystem。 ## 2)需求分析: 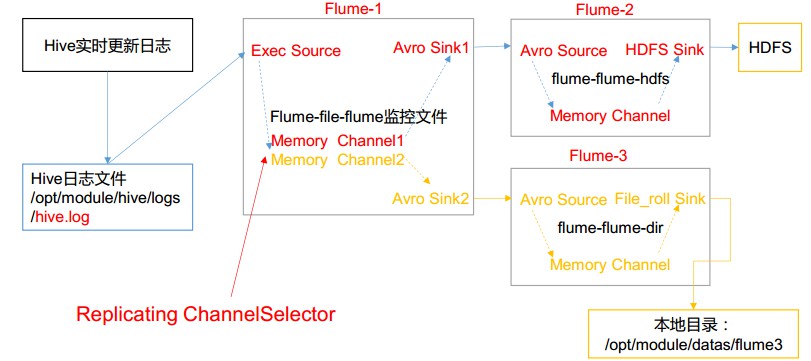 ## 3)实现步骤: ### 1.准备工作 在/usr/local/flume/job 目录下创建 group1 文件夹: ```bash nbu@ecs:/usr/local/flume/job$ mkdir group1 nbu@ecs:/usr/local/flume/job$ cd group1 ``` 在/usr/local/flume/datas/目录下创建 flume3 文件夹: ```bash nbu@ecs:/usr/local/flume/job/group1$ cd /usr/local/flume nbu@ecs:/usr/local/flume$ mkdir -p datas/flume3 ``` ### 2.创建 flume-file-flume.conf 配置 1 个接收日志文件的 source 和两个 channel、两个 sink,分别输送给 flume-flume-hdfs 和 flume-flume-dir。 编辑配置文件 ```bash nbu@ecs:~$ cd /usr/local/flume/job/group1/ nbu@ecs:/usr/local/flume/job/group1$ vim flume-file-flume.conf ``` 添加如下内容: ```bash # Name the components on this agent a1.sources = r1 a1.sinks = k1 k2 a1.channels = c1 c2 # 将数据流复制给所有 channel a1.sources.r1.selector.type = replicating # Describe/configure the source a1.sources.r1.type = exec a1.sources.r1.command = tail -F /usr/local/hive/logs/hive.log a1.sources.r1.shell = /bin/bash -c # Describe the sink # sink 端的 avro 是一个数据发送者 a1.sinks.k1.type = avro a1.sinks.k1.hostname = ecs a1.sinks.k1.port = 4141 a1.sinks.k2.type = avro a1.sinks.k2.hostname = ecs a1.sinks.k2.port = 4142 # Describe the channel a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 a1.channels.c2.type = memory a1.channels.c2.capacity = 1000 a1.channels.c2.transactionCapacity = 100 # Bind the source and sink to the channel a1.sources.r1.channels = c1 c2 a1.sinks.k1.channel = c1 a1.sinks.k2.channel = c2 ``` ### 3.创建 flume-flume-hdfs.conf 配置上级 Flume 输出的 Source, 输出是到 HDFS 的 Sink。 编辑配置文件: ```bash nbu@ecs:/usr/local/flume/job/group1$ vim flume-flume-hdfs.conf ``` 添加如下内容: ```bash # Name the components on this agent a2.sources = r1 a2.sinks = k1 a2.channels = c1 # Describe/configure the source # source 端的 avro 是一个数据接收服务 a2.sources.r1.type = avro a2.sources.r1.bind = hadoop102 a2.sources.r1.port = 4141 # Describe the sink a2.sinks.k1.type = hdfs a2.sinks.k1.hdfs.path = hdfs://hadoop102:9000/flume2/%Y%m%d/%H #上传文件的前缀 a2.sinks.k1.hdfs.filePrefix = flume2- #是否按照时间滚动文件夹 a2.sinks.k1.hdfs.round = true #多少时间单位创建一个新的文件夹 a2.sinks.k1.hdfs.roundValue = 1 #重新定义时间单位 a2.sinks.k1.hdfs.roundUnit = hour #是否使用本地时间戳 a2.sinks.k1.hdfs.useLocalTimeStamp = true #积攒多少个 Event 才 flush 到 HDFS 一次 a2.sinks.k1.hdfs.batchSize = 100 #设置文件类型,可支持压缩 a2.sinks.k1.hdfs.fileType = DataStream #多久生成一个新的文件 a2.sinks.k1.hdfs.rollInterval = 600 #设置每个文件的滚动大小大概是 128M a2.sinks.k1.hdfs.rollSize = 134217700 #文件的滚动与 Event 数量无关 a2.sinks.k1.hdfs.rollCount = 0 # Describe the channel a2.channels.c1.type = memory a2.channels.c1.capacity = 1000 a2.channels.c1.transactionCapacity = 100 # Bind the source and sink to the channel a2.sources.r1.channels = c1 a2.sinks.k1.channel = c1 ``` ### 4.创建 flume-flume-dir.conf 配置上级 Flume 输出的 Source, 输出是到本地目录的 Sink。 编辑配置文件: ```bash nbu@ecs:/usr/local/flume/job/group1$ vim flume-flume-dir.conf ``` 添加如下内容: ```bash # Name the components on this agent a3.sources = r1 a3.sinks = k1 a3.channels = c2 # Describe/configure the source a3.sources.r1.type = avro a3.sources.r1.bind = hadoop102 a3.sources.r1.port = 4142 # Describe the sink a3.sinks.k1.type = file_roll a3.sinks.k1.sink.directory = /opt/module/data/flume3 # Describe the channel a3.channels.c2.type = memory a3.channels.c2.capacity = 1000 a3.channels.c2.transactionCapacity = 100 # Bind the source and sink to the channel a3.sources.r1.channels = c2 a3.sinks.k1.channel = c2 ``` 提示:输出的本地目录必须是已经存在的目录,如果该目录不存在,并不会创建新的目录。 ### 5.执行配置文件 分别启动对应的 flume 进程: flume-flume-dir, flume-flume-hdfs, flume-file-flume。 ```bash nbu@ecs:/usr/local/flume$ bin/flume-ng agent --conf conf/ --name a3 --conf-file job/group1/flume-flume-dir.conf nbu@ecs:/usr/local/flume$ bin/flume-ng agent --conf conf/ --name a2 --conf-file job/group1/flume-flume-hdfs.conf nbu@ecs:/usr/local/flume$ bin/flume-ng agent --conf conf/ --name a1 --conf-file job/group1/flume-file-flume.conf ``` ### 6.启动 Hadoop 和 Hive ```bash nbu@ecs:~$ cd /usr/local/hadoop/ nbu@ecs:/usr/local/hadoop$ sbin/start-dfs.sh nbu@ecs:/usr/local/hadoop$ sbin/start-yarn.sh nbu@ecs:/usr/local/hadoop$ cd /usr/local/hive/ nbu@ecs:/usr/local/hive$ bin/hive hive (default)> ``` ### 7.检查 HDFS 上数据 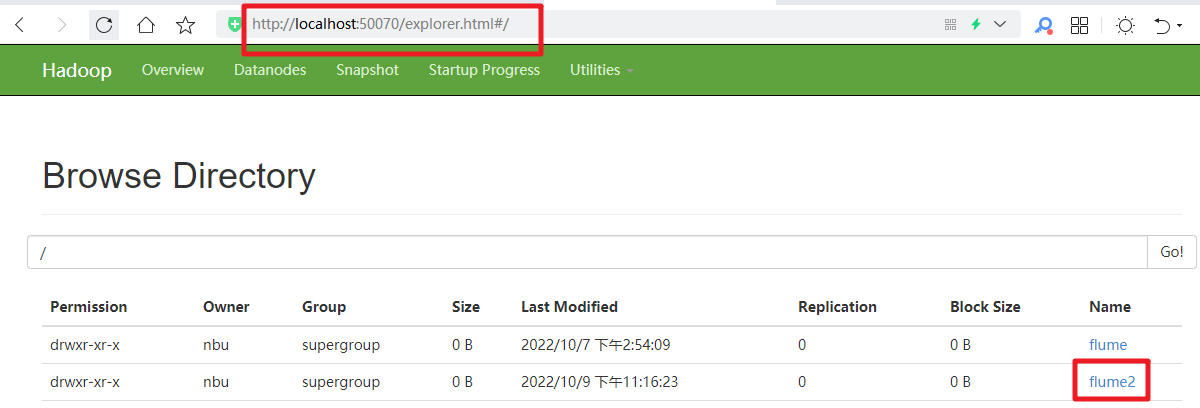 ### 8.检查/opt/module/datas/flume3 目录中数据 ```bash nbu@ecs:~$ ll /usr/local/flume/datas/flume3/ total 20 drwxrwxr-x 2 nbu nbu 4096 Oct 9 23:19 ./ drwxrwxr-x 3 nbu nbu 4096 Oct 9 22:53 ../ -rw-rw-r-- 1 nbu nbu 0 Oct 9 23:14 1665328442213-1 -rw-rw-r-- 1 nbu nbu 0 Oct 9 23:18 1665328442213-10 -rw-rw-r-- 1 nbu nbu 0 Oct 9 23:19 1665328442213-11 -rw-rw-r-- 1 nbu nbu 0 Oct 9 23:19 1665328442213-12 -rw-rw-r-- 1 nbu nbu 0 Oct 9 23:14 1665328442213-2 -rw-rw-r-- 1 nbu nbu 1560 Oct 9 23:15 1665328442213-3 -rw-rw-r-- 1 nbu nbu 0 Oct 9 23:15 1665328442213-4 -rw-rw-r-- 1 nbu nbu 0 Oct 9 23:16 1665328442213-5 -rw-rw-r-- 1 nbu nbu 2294 Oct 9 23:16 1665328442213-6 -rw-rw-r-- 1 nbu nbu 700 Oct 9 23:17 1665328442213-7 -rw-rw-r-- 1 nbu nbu 0 Oct 9 23:17 1665328442213-8 -rw-rw-r-- 1 nbu nbu 0 Oct 9 23:18 1665328442213-9 ```
上一篇:
08 openGauss数据库备份恢复指导手册
下一篇:
08-InfluxDB数据库管理
文档导航

 浙ICP备案2024056857号
浙ICP备案2024056857号
 浙公网安备33020502001085号
浙公网安备33020502001085号