大数据学习
bigdata learning
Toggle navigation
大数据学习
主页
openGauss数据库
Flume
MongoDB
Hadoop
数据库实验
Kafka
Zookeeper
Hbase
Manual
Spark
Neo4j
InfluxDB
RabbitMQ
Flink
About Me
归档
标签
06-Spark常见问题-解决方法
无
2023-04-24 13:04:29
27
0
0
bigdata
## 解决 sbt 无法下载依赖包的问题 按照官网教程安装 sbt 0.13.9 后,运行时会出现如下错误: Getting org.scala-sbt sbt 0.13.9 ... :: problems summary :: :::: WARNINGS module not found: org.scala-sbt#sbt;0.13.9 ==== local: tried /home/hadoop/.ivy2/local/org.scala-sbt/sbt/0.13.9/ivys/ivy.xml -- artifact org.scala-sbt#sbt;0.13.9!sbt.jar: /home/hadoop/.ivy2/local/org.scala-sbt/sbt/0.13.9/jars/sbt.jar ... :::::::::::::::::::::::::::::::::::::::::::::: :: UNRESOLVED DEPENDENCIES :: :::::::::::::::::::::::::::::::::::::::::::::: :: org.scala-sbt#sbt;0.13.9: not found :::::::::::::::::::::::::::::::::::::::::::::: :::: ERRORS Server access Error: java.security.ProviderException: java.security.KeyException url=https://jcenter.bintray.com/org/scala-sbt/sbt/0.13.9/sbt-0.13.9.pom ... :: USE VERBOSE OR DEBUG MESSAGE LEVEL FOR MORE DETAILS unresolved dependency: org.scala-sbt#sbt;0.13.9: not found Error during sbt execution: Error retrieving required libraries (see /home/hadoop/.sbt/boot/update.log for complete log) Error: Could not retrieve sbt 0.13.9 用浏览器访问给出的链接,也是 404 的状态,这就需要修改 repositories 的地址。另外一个可能出现的问题是提示 “Server access Error: java.security.ProviderException:java.security.KeyException”,但通过浏览器可以访问,这应该是 https 导致的问题,可以改成通过 http 访问。 执行如下命令下载官方的 sbt-launch.jar,并进行解压: ```shell $ cd /usr/local/sbt $ wget https://repo.typesafe.com/typesafe/ivy-releases/org.scala-sbt/sbt-launch/0.13.9/sbt-launch.jar -O ./sbt-launch.jar # 下载 $ unzip -q ./sbt-launch.jar # 解压 ``` 需要修改其中的 ./sbt/sbt.boot.properties 文件(`vim ./sbt/sbt.boot.properties`),将[repositories] 处修改为如下内容(即增加了一条 oschina 镜像,并且将原有的 https 镜像都改为相应的 http 版): [repositories] local oschina: http://maven.oschina.net/content/groups/public/ jcenter: http://jcenter.bintray.com/ typesafe-ivy-releases: http://repo.typesafe.com/typesafe/ivy-releases/, [organization]/[module]/[revision]/[type]s/[artifact](-[classifier]).[ext], bootOnly maven-central: http://repo1.maven.org/maven2/ 保存后,重新打包 jar: ```shell $ rm ./sbt-launch.jar # 删除旧的 $ jar -cfM ./sbt-launch.jar . # 重新打包 $ ls | grep -v "sbt-launch.jar" | xargs rm -r # 解压后的文件已无用,删除 ``` 注意打包时,需要使用 -M 参数,否则 ./META-INF/MANIFEST.MF 会被修改,导致运行时会出现 “./sbt-launch.jar 中没有主清单属性” 的错误。 重新打包后,接着创建 sbt 脚本并赋予可执行权限,在此就不再复试。 ### 使用 sbt 打包 Scala 程序 为保证 sbt 能正常运行,先执行如下命令检查整个应用程序的文件结构: ```shell $ cd ~/sparkapp $ find . ``` 文件结构应如下图所示: 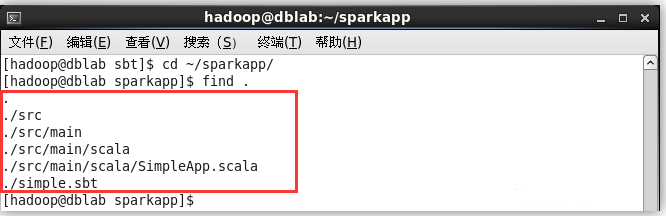 接着,我们就可以通过如下代码将整个应用程序打包成 JAR(首次运行同样需要下载依赖包,如果这边遇到网络问题无法成功,也请下载上述安装 sbt ,提到的离线依赖包 sbt-0.13.9-repo.tar.gz ): ```shell $ /usr/local/sbt/sbt package ``` 打包成功的话,会输出如下图内容: 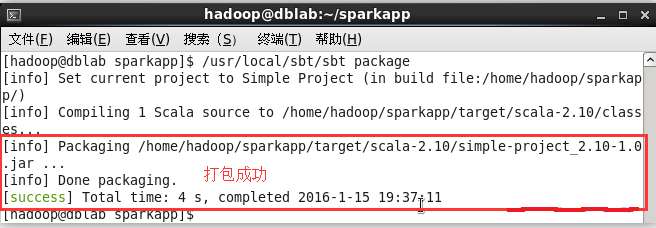 生成的 jar 包的位置为 ~/sparkapp/target/scala-2.10/simple-project_2.10-1.0.jar。 ### 通过 spark-submit 运行程序 最后,我们就可以将生成的 jar 包通过 spark-submit 提交到 Spark 中运行了,命令如下: ```shell $ /usr/local/spark/bin/spark-submit --class "SimpleApp" ~/sparkapp/target/scala-2.10/simple-project_2.10-1.0.jar $ # 输出信息太多,可以通过如下命令过滤直接查看结果 $ /usr/local/spark/bin/spark-submit --class "SimpleApp" ~/sparkapp/target/scala-2.10/simple-project_2.10-1.0.jar 2>&1 | grep "Lines with a:" ``` 最终得到的结果如下: Lines with a: 58, Lines with b: 26 自此,你就完成了你的第一个 Spark 应用程序了。 ## 进阶学习 Spark 官网提供了完善的学习文档(许多技术文档都只有英文版本,因此学会查看英文文档也是学习大数据技术的必备技能): - 如果想对 Spark 的 API 有更深入的了解,可查看的 [Spark 编程指南(Spark Programming Guide)](http://spark.apache.org/docs/latest/programming-guide.html); - 如果你想对 Spark SQL 的使用有更多的了解,可以查看 [Spark SQL、DataFrames 和 Datasets 指南](http://spark.apache.org/docs/latest/sql-programming-guide.html); - 如果你想对 Spark Streaming 的使用有更多的了解,可以查看 [Spark Streaming 编程指南](http://spark.apache.org/docs/latest/streaming-programming-guide.html); - 如果需要在集群环境中运行 Spark 程序,可查看官网的 [Spark 集群部署](http://spark.apache.org/docs/latest/cluster-overview.html)
上一篇:
06-Neo4j-CREATE-MATCH-RETURN命令
下一篇:
06-Zookeeper-session基本原理
文档导航

 浙ICP备案2024056857号
浙ICP备案2024056857号
 浙公网安备33020502001085号
浙公网安备33020502001085号