大数据学习
bigdata learning
Toggle navigation
大数据学习
主页
openGauss数据库
Flume
MongoDB
Hadoop
数据库实验
Kafka
Zookeeper
Hbase
Manual
Spark
Neo4j
InfluxDB
RabbitMQ
Flink
About Me
归档
标签
01-Flink下载安装
Flink
2023-05-17 14:15:10
45
0
0
bigdata
Flink
Apache Flink 是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算。Flink 被设计为在所有常见的集群环境中运行,Apache Flin 是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算。Flink 被设计为在所有常见的集群环境中运行,以内存中速度和任何规模执行计算。 # 下载和安装 1. 手动下载 下载地址:[Apache Flink](https://flink.apache.org/downloads.html "Apache Flink") 2. [点击这里从百度云盘下载](https://pan.baidu.com/s/1QGzNZM95_IJlkRjawzg9Rw)(提取码:tpag) 手动下载移动到/opt/software 目录下准备安装 `flink-*-bin-scala*.tgz`表示是编译之后的安装包,可以直接用来部署。 这里以 `flink-1.10.1-bin-scala_2.12.tgz'作为示例。 `flink-1.10.1-bin-scala_2.12.tgz` 文件解压至 `/opt` 目录下 修改 flink 目录的所属用户和所属组 ``` nbu@ecs:~$ sudo tar -xzvf /opt/software/flink-1.10.1-bin-scala_2.12.tgz -C /usr/local nbu@ecs:~$cd /usr/local nbu@ecs:/usr/local$ sudo mv flink-1.10.1 flink nbu@ecs:/usr/local$ sudo chown -R nbu:nbu flink ``` **启动和关停本地集群** 使用如下命令启动本地集群 ```bash nbu@ecs:~$/usr/local/flink/bin/start-cluster.sh Starting cluster. Starting standalonesession daemon on host ecs. Starting taskexecutor daemon on host ecs. ``` 在浏览器输入 localhost:8081 (127.0.0.1:8081) 以访问其 **web UI** 界面。 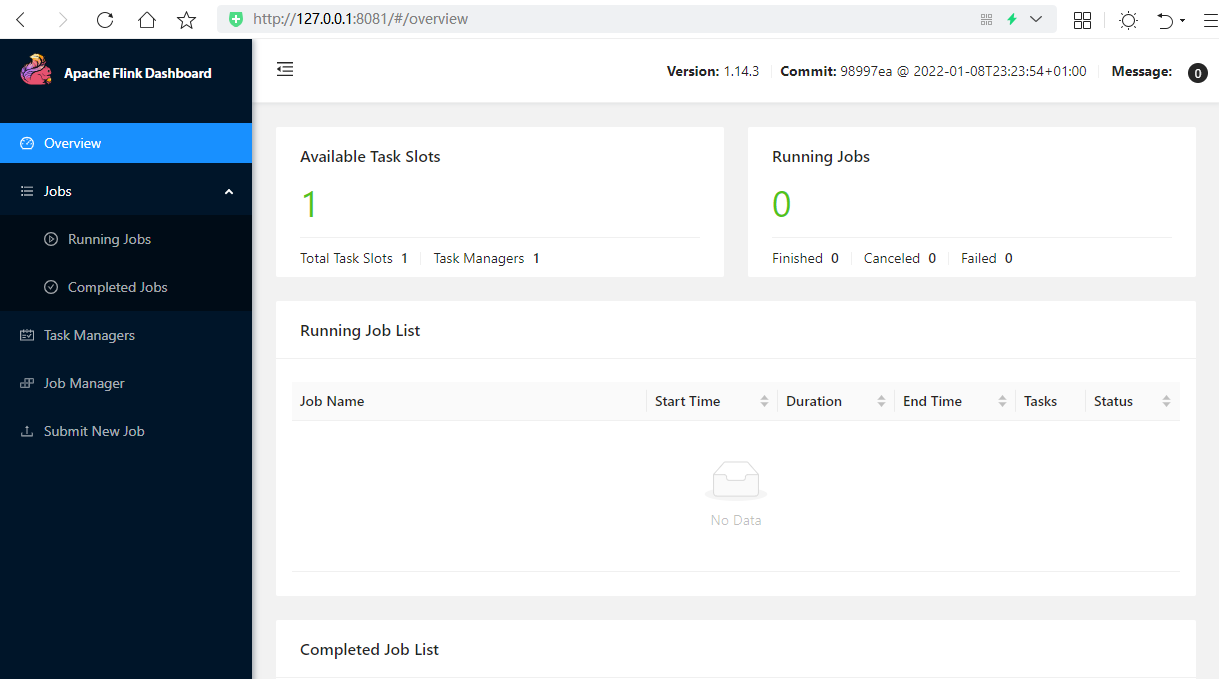 > 关闭集群 > ```bash > nbu@ecs:/usr/local/flink$ bin/stop-cluster.sh > ``` # 测试 flink安装包的examples目录下有很多官方开发好的案例,我们可以拿来测试我们的集群SocketWindowWordCount.jar:官方这个例子是通过监听socket的方式测试。 ```bash # 另开启一个终端利用netcat监听9000端口 nbu@ecs:~$ nc -l 9000 ``` ```bash nbu@ecs:/usr/local/flink$ bin/flink run examples/streaming/SocketWindowWordCount.jar --hostname 127.0.0.1 --port 9000 ``` 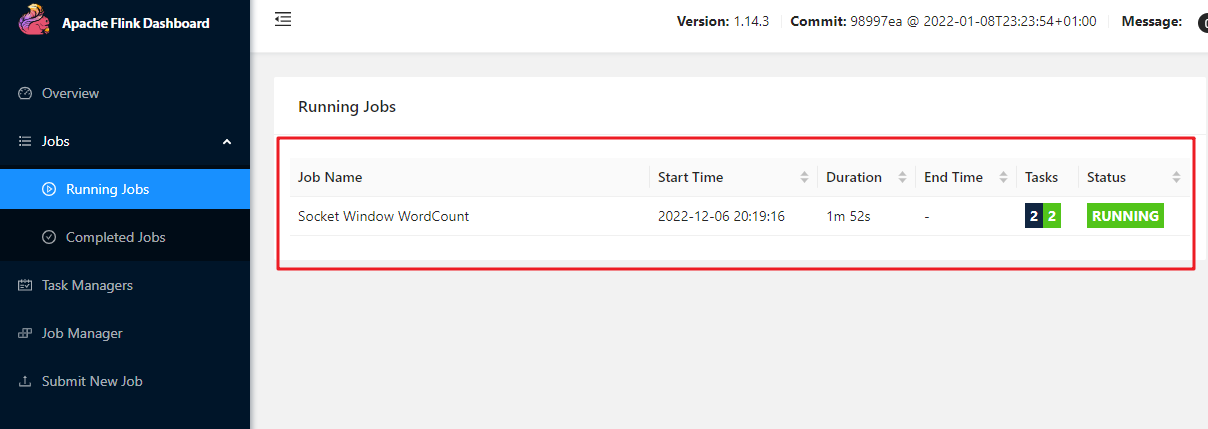 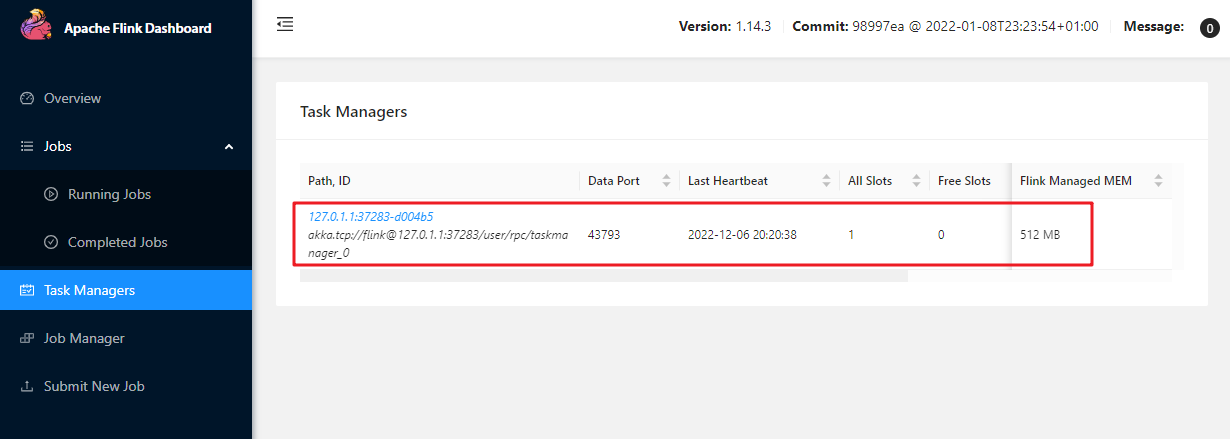 在netcat窗口中输入的单词会在wui的TaskManagers Stdout中输出 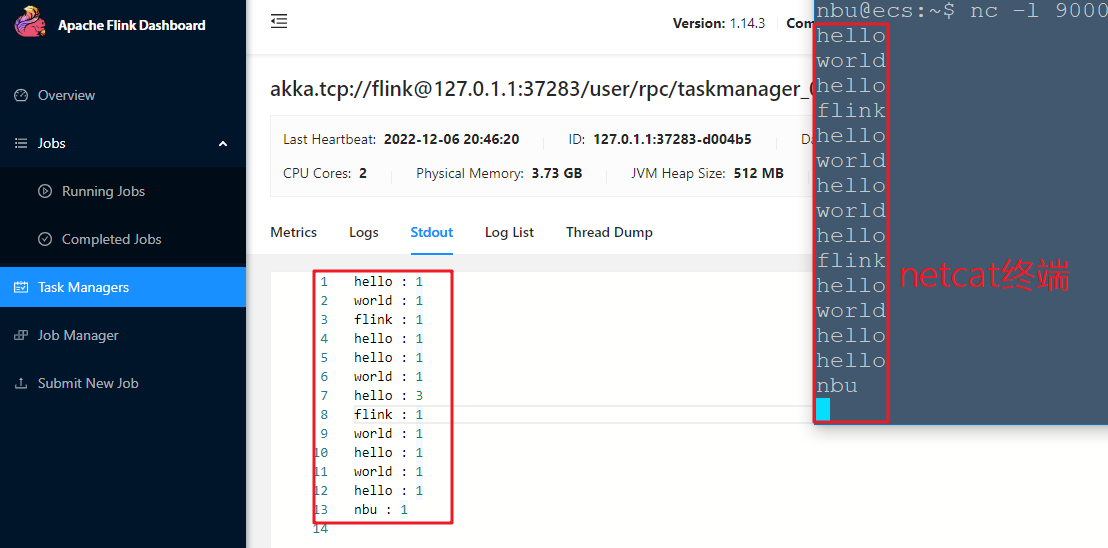
上一篇:
01-5 在ECS上安装部署openGauss数据库指导手册
下一篇:
01-Flume概述
文档导航

 浙ICP备案2024056857号
浙ICP备案2024056857号
 浙公网安备33020502001085号
浙公网安备33020502001085号