大数据学习
bigdata learning
Toggle navigation
大数据学习
主页
openGauss数据库
Flume
MongoDB
Hadoop
数据库实验
Kafka
Zookeeper
Hbase
Manual
Spark
Neo4j
InfluxDB
RabbitMQ
Flink
About Me
归档
标签
11-Zookeeper数据同步与Leader选举
Zookeeper
2022-10-17 19:47:21
25
0
0
bigdata
Zookeeper
在 Zookeeper 中,主要依赖 ZAB 协议来实现分布式数据一致性。 ZAB 协议分为两部分: * 消息广播 * 崩溃恢复 # 消息广播 Zookeeper 使用单一的主进程 Leader 来接收和处理客户端所有事务请求,并采用 ZAB 协议的原子广播协议,将事务请求以 Proposal 提议广播到所有 Follower 节点,当集群中有过半的 Follower 服务器进行正确的 ACK 反馈,那么 Leader 就会再次向所有的 Follower 服务器发送 commit 消息,将此次提案进行提交。这个过程可以简称为 2pc 事务提交,整个流程可以参考下图,注意 Observer 节点只负责同步 Leader 数据,不参与 2PC 数据同步过程。 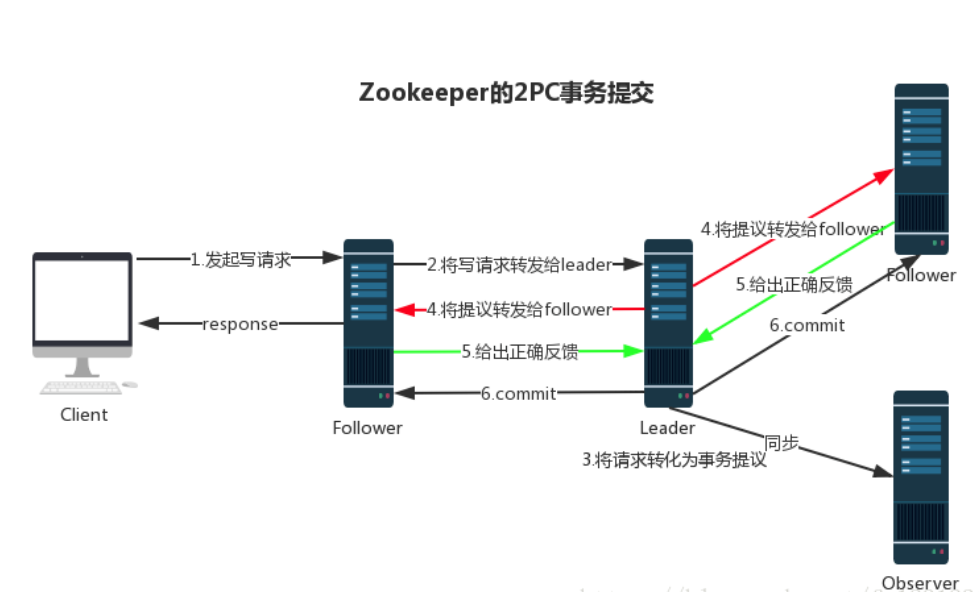 # 崩溃恢复 在正常情况消息广播情况下能运行良好,但是一旦 Leader 服务器出现崩溃,或者由于网络原理导致 Leader 服务器失去了与过半 Follower 的通信,那么就会进入崩溃恢复模式,需要选举出一个新的 Leader 服务器。在这个过程中可能会出现两种数据不一致性的隐患,需要 ZAB 协议的特性进行避免。 * 1、Leader 服务器将消息 commit 发出后,立即崩溃 * 2、Leader 服务器刚提出 proposal 后,立即崩溃 ZAB 协议的恢复模式使用了以下策略: * 1、选举 zxid 最大的节点作为新的 leader * 2、新 leader 将事务日志中尚未提交的消息进行处理 zookeeper 的 leader 选举存在两个阶段,一个是服务器启动时 leader 选举,另一个是运行过程中 leader 服务器宕机。在分析选举原理前,先介绍几个重要的参数。 * 服务器 ID(myid):编号越大在选举算法中权重越大 * 事务 ID(zxid):值越大说明数据越新,权重越大 * 逻辑时钟 (epoch-logicalclock):同一轮投票过程中的逻辑时钟值是相同的,每投完一次值会增加 **选举状态:** * **LOOKING**: 竞选状态 * **FOLLOWING**: 随从状态,同步 leader 状态,参与投票 * **OBSERVING**: 观察状态,同步 leader 状态,不参与投票 * **LEADING**: 领导者状态 # leader 选举 ## 1、服务器启动时的 leader 选举 每个节点启动的时候都 LOOKING 观望状态,接下来就开始进行选举主流程。这里选取三台机器组成的集群为例。第一台服务器 server1 启动时,无法进行 leader 选举,当第二台服务器 server2 启动时,两台机器可以相互通信,进入 leader 选举过程。 * (1)每台 server 发出一个投票,由于是初始情况,server1 和 server2 都将自己作为 leader 服务器进行投票,每次投票包含所推举的服务器 myid、zxid、epoch,使用(myid,zxid)表示,此时 server1 投票为(1,0),server2 投票为(2,0),然后将各自投票发送给集群中其他机器。 * (2)接收来自各个服务器的投票。集群中的每个服务器收到投票后,首先判断该投票的有效性,如检查是否是本轮投票(epoch)、是否来自 LOOKING 状态的服务器。 * (3)分别处理投票。针对每一次投票,服务器都需要将其他服务器的投票和自己的投票进行对比,对比规则如下: * a. 优先比较 epoch * b. 检查 zxid,zxid 比较大的服务器优先作为 leader * c. 如果 zxid 相同,那么就比较 myid,myid 较大的服务器作为 leader 服务器 * (4)统计投票。每次投票后,服务器统计投票信息,判断是都有过半机器接收到相同的投票信息。server1、server2 都统计出集群中有两台机器接受了(2,0)的投票信息,此时已经选出了 server2 为 leader 节点。 * (5)改变服务器状态。一旦确定了 leader,每个服务器响应更新自己的状态,如果是 follower,那么就变更为 FOLLOWING,如果是 Leader,变更为 LEADING。此时 server3 继续启动,直接加入变更自己为 FOLLOWING。 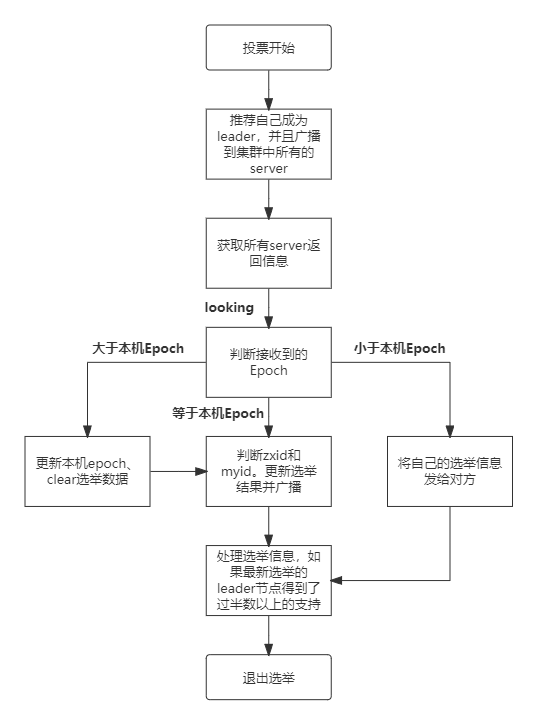 ## 2、运行过程中的 leader 选举 当集群中 leader 服务器出现宕机或者不可用情况时,整个集群无法对外提供服务,进入新一轮的 leader 选举。 * (1)变更状态。leader 挂后,其他非 Oberver 服务器将自身服务器状态变更为 LOOKING。 * (2)每个 server 发出一个投票。在运行期间,每个服务器上 zxid 可能不同。 * (3)处理投票。规则同启动过程。 * (4)统计投票。与启动过程相同。 * (5)改变服务器状态。与启动过程相同。
上一篇:
11-Neo4j-UNION-LIMIT-SKIP
下一篇:
12-Flume案例-自定义Sink
文档导航

 浙ICP备案2024056857号
浙ICP备案2024056857号
 浙公网安备33020502001085号
浙公网安备33020502001085号