大数据学习
bigdata learning
Toggle navigation
大数据学习
主页
openGauss数据库
Flume
MongoDB
Hadoop
数据库实验
Kafka
Zookeeper
Hbase
Manual
Spark
Neo4j
InfluxDB
RabbitMQ
Flink
About Me
归档
标签
03-Zookeeper服务端集群搭建*
Zookeeper
2022-10-17 19:47:21
32
0
0
bigdata
Zookeeper
本章节将示范三台 zookeeper 服务端集群搭建步骤。 所需准备工作,创建三台虚拟机环境并安装好 java 开发工具包 JDK,可以使用 VM 或者 vagrant+virtualbox 搭建 centos/ubuntu 环境,本案例基于宿主机 windows10 系统同时使用 vagrant+virtualbox 搭建的 centos7 环境,如果直接使用云服务器或者物理机同理。 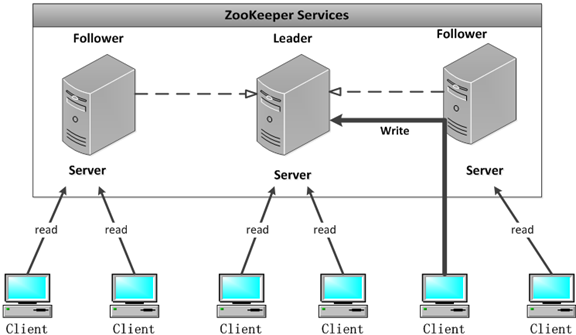 # 步骤一 准备三台 zookeeper 环境和并按照上一教程下载 zookeeper 压缩包,三台集群 centos 环境如下: 机器一:192.168.3.33  机器二:192.168.3.35  机器三:192.168.3.37  提示: 查看 ip 地址可以用 ifconfig 命令。 # 步骤二: 别修改 zoo.cfg 配置信息 zookeeper 的三个端口作用 * 1、2181 : 对 client 端提供服务 * 2、2888 : 集群内机器通信使用 * 3、3888 : 选举 leader 使用 按 server.id = ip:port:port 修改集群配置文件: 三台虚拟机 zoo.cfg 文件末尾添加配置: ```bash server.1=192.168.3.33:2888:3888 server.2=192.168.3.35:2888:3888 server.3=192.168.3.37:2888:3888 ``` 根据 id 和对应的地址分别配置 myid ```bash vim /tmp/zookeeper/myid ``` 本案例配置完成后查询显示如下: IP 192.168.3.33 机器配置 myid,因为这台机器上个教程单机启动过,所以出现 version-2,没有也没关系。  IP 192.168.3.35 机器配置 myid  IP 192.168.3.37 机器配置 myid  # 步骤三: 启动集群 启动前需要关闭防火墙 (生产环境需要打开对应端口) ```bash systemctl stop firewalld ``` 启动 192.168.3.33 并查看日志,此时日志出现报错是正常现象,因为另外两台还没启动,暂时连接不上。 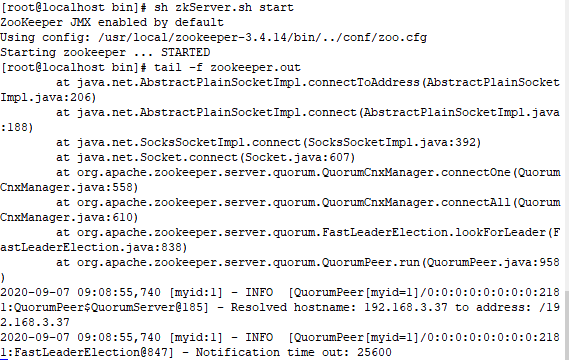 另两台分别启动后,查看三台机器状态: IP 192.168.3.33 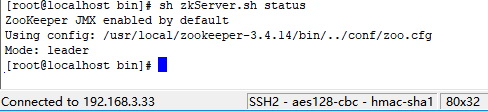 IP 192.168.3.35 
上一篇:
03-Spark-SparkSQL
下一篇:
04 openGauss数据库安全指导手册
文档导航

 浙ICP备案2024056857号
浙ICP备案2024056857号
 浙公网安备33020502001085号
浙公网安备33020502001085号