大数据学习
bigdata learning
Toggle navigation
大数据学习
主页
openGauss数据库
Flume
MongoDB
Hadoop
数据库实验
Kafka
Zookeeper
Hbase
Manual
Spark
Neo4j
InfluxDB
RabbitMQ
Flink
About Me
归档
标签
03-Flink-StreamWordCount编程
Flink
Java
2023-05-17 14:15:10
36
0
0
bigdata
Flink
Java
**一、建立WordCount工程** ```bash # 创建工程文件夹~/bigdata/flink/wordcount nbu@ecs:~$ mkdir -p bigdata/flink/wordcount nbu@ecs:~$ cd bigdata/flink/wordcount # 创建项目package org.nbubigdata.flink nbu@ecs:~/bigdata/flink/wordcount$ mkdir -p src/org/nbubigdata/flink # 创建输出文件夹classes 用于保存编译后的class文件及jar包 nbu@ecs:~/bigdata/flink/wordcount$ mkdir classes nbu@ecs:~/bigdata/flink/wordcount$ cd src/org/nbubigdata/flink nbu@ecs:~/bigdata/flink/wordcount/src/org/nbubigdata/flink$ vim StreamWordCount.java ``` 输入如下内容: ```java package org.nbubigdata.flink package org.nbubigdata.flink; import org.apache.flink.api.common.typeinfo.Types; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.datastream.KeyedStream; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.util.Collector; import java.util.Arrays; public class StreamWordCount { public static void main(String[] args) throws Exception { // 1. 创建流式执行环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // 2. 读取文本流 DataStreamSource<String> lineDSS = env.socketTextStream("localhost", 7777); // 3. 转换数据格式 SingleOutputStreamOperator<Tuple2<String, Long>> wordAndOne = lineDSS .flatMap((String line, Collector<String> words) -> { Arrays.stream(line.split(" ")).forEach(words::collect); }) .returns(Types.STRING).map(word -> Tuple2.of(word, 1L)) .returns(Types.TUPLE(Types.STRING, Types.LONG)); // 4. 分组 KeyedStream<Tuple2<String, Long>, String> wordAndOneKS = wordAndOne .keyBy(t -> t.f0); // 5. 求和 SingleOutputStreamOperator<Tuple2<String, Long>> result = wordAndOneKS .sum(1); // 6. 打印 result.print(); // 7. 执行 env.execute(); } } ``` **二、使用 javac 命令进行编译** 配置CLASSPATH ```bash nbu@ecs:~$ vim ~/.bashrc # 在文件最后加上 export FLINK_HOME=/usr/local/flink export CLASSPATH=$CLASSPATH:$FLINK_HOME/lib/* nbu@ecs:~$ source ~/.bashrc ``` Javac编译 ```bash nbu@ecs:~/bigdata/flink/wordcount/src/org/nbubigdata/flink$ cd ~/bigdata/flink/wordcount nbu@ecs:~/bigdata/flink/wordcount$ javac -d ./classes ./src/org/nbubigdata/flink/StreamWordCount.java ``` 编译完成后可以看到`~/bigdata/flink/wordcount/classes/org/nbubigdata/flink/` 下多了一个`StreamWordCount.java`文件 **三、打成可运行的 jar 包** ```bash nbu@ecs:~/bigdata/flink/wordcount/classes$ vim MANIFEST.mf ``` 经过上述步骤以后,可以先在classes目录下编写一个MANIFEST.mf 文件内容如下,这里要注意每个冒号后面的英文空格,每行结束都要有个回车。 ``` Manifest-Version: 1.0 Class-Path: Created-By: 1.8.0_312 (Sun Microsystems Inc.) Main-Class: org.nbubigdata.flink.StreamWordCount ``` 输入以下命令,可在classes文件夹下生成HelloWorld.jar包 ```bash nbu@ecs:~/bigdata/flink/wordcount/classes$ jar -cvfm StreamWordCount.jar MANIFEST.mf org added manifest adding: org/(in = 0) (out= 0)(stored 0%) adding: org/nbubigdata/(in = 0) (out= 0)(stored 0%) adding: org/nbubigdata/flink/(in = 0) (out= 0)(stored 0%) adding: org/nbubigdata/flink/StreamWordCount.class(in = 5541) (out= 2159)(deflated 61%) adding: org/nbubigdata/flink/WordCount.class(in = 1444) (out= 709)(deflated 50%) adding: org/nbubigdata/flink/WordCount$MyFlatMapper.class(in = 1481) (out= 676)(deflated 54%) ``` > `jar -cfm`中`f`和`m`的次序要与`WordCount.jar`和`MANIFEST.mf`相对应 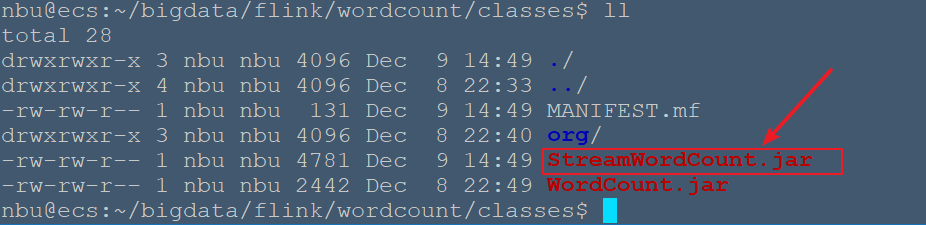 **四、命令行提交jar包** ```bash # 开启Flink集群 nbu@ecs:~/helloworld$/usr/local/flink/bin/start-cluster.sh Starting cluster. Starting standalonesession daemon on host ecs. Starting taskexecutor daemon on host ecs. ``` 另开启一个netcat终端,输入如下命令 ``` nbu@ecs:~$ nc -lk 7777 ``` 在原Flink终端提交`StreamWordCount.jar` ```bash nbu@ecs:~/bigdata/flink/wordcount/classes$ /usr/local/flink/bin/flink run StreamWordCount.jar ``` 在netcat终端 输入 ```bash hello world hello flink hello nbu hello world hello flink hello nbu ``` 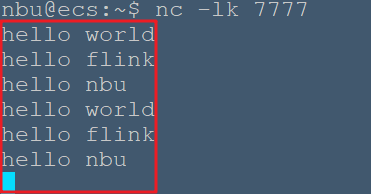 可在`/usr/local/flink/log/flink-nbu-taskexecutor-0-ecs.out`中看到输出结果 ``` nbu@ecs:~/bigdata/flink/wordcount/classes$ tail -f /usr/local/flink/log/flink-*-taskexecutor-*.out ``` 输出如下: 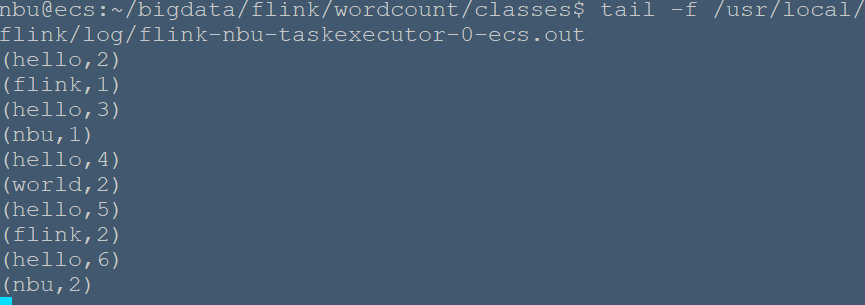
上一篇:
03 openGauss数据库开发指导手册
下一篇:
03-Flume案例-监控端口数据
文档导航

 浙ICP备案2024056857号
浙ICP备案2024056857号
 浙公网安备33020502001085号
浙公网安备33020502001085号