大数据学习
bigdata learning
Toggle navigation
大数据学习
主页
openGauss数据库
Flume
MongoDB
Hadoop
数据库实验
Kafka
Zookeeper
Hbase
Manual
Spark
Neo4j
InfluxDB
RabbitMQ
Flink
About Me
归档
标签
多流处理
无
2024-04-13 14:01:29
33
0
0
bigdata
### 多流处理 > Written by 黄俊仁,2024/04/13 这个程序展示了如何在 Apache Flink 中使用 `connect` 操作符将两个不同的数据流连接起来,并通过 `CoMapFunction` 分别对这两个流的元素进行处理。每个流的数据通过 `NBUSource` 产生,并分别加上前缀 "Stream1: " 和 "Stream2: " 来区分来源,最后将处理过的数据统一输出到控制台。这个示例演示了 Flink 处理多源数据流并在单个作业中应用不同逻辑的能力。 ```java package org.nbubigdata.flink; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.datastream.ConnectedStreams; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.functions.co.CoMapFunction; public class MultiStreamTransformation { public static void main(String[] args) throws Exception { // 设置Flink流执行环境 final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // 创建两个使用NBUSource的数据流 DataStream<String> stream1 = env.addSource(new NBUSource()); DataStream<String> stream2 = env.addSource(new NBUSource()); // 使用connect操作符连接两个流 ConnectedStreams<String, String> connectedStreams = stream1.connect(stream2); // 使用CoMapFunction对连接后的流进行处理 DataStream<String> resultStream = connectedStreams.map(new CoMapFunction<String, String, String>() { // 第一个流中的元素使用这个方法处理 @Override public String map1(String value) { return "Stream1: " + value; } // 第二个流中的元素使用这个方法处理 @Override public String map2(String value) { return "Stream2: " + value; } }); // 输出处理后的结果 resultStream.print(); // 执行Flink程序 env.execute("MultiStream Transformation Example"); } } ``` 运行上述程序,可以在控制台中观察到如下的输出信息。 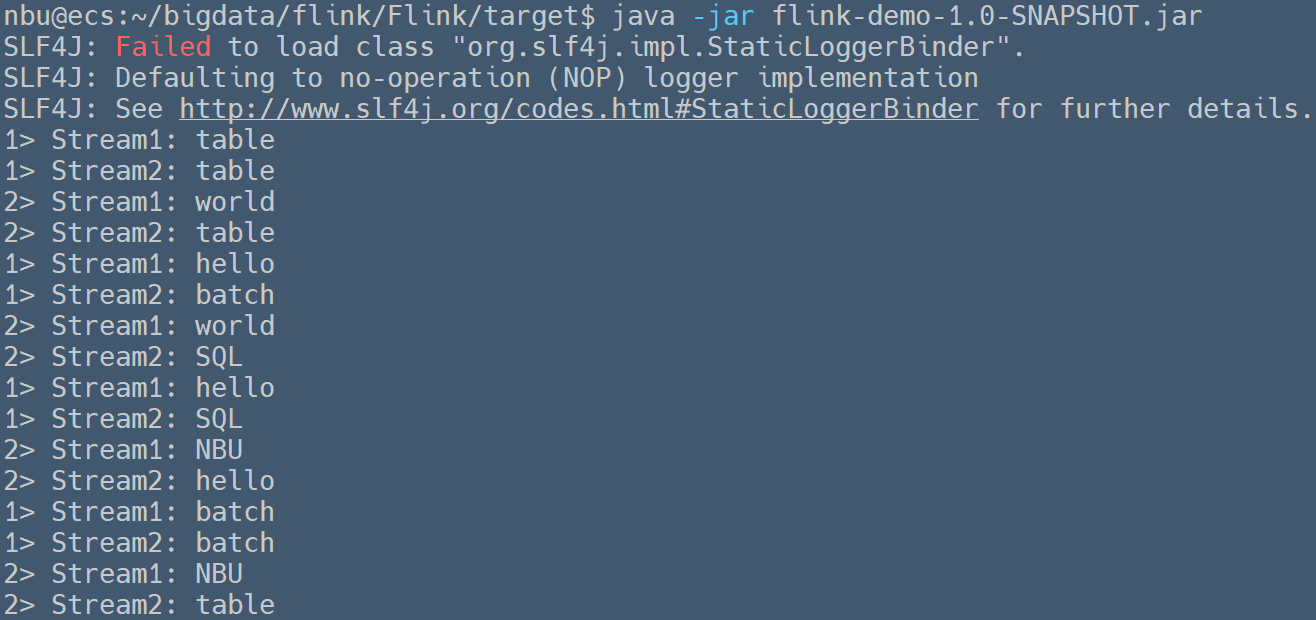 可以观察到,两个使用 `NBUSource` 的数据流被连接(`connect`)起来。 `CoMapFunction` 为来自第一个数据流的每个字符串添加前缀 `"Stream1: "`,并为来自第二个数据流的每个字符串添加前缀 `"Stream2: "`。
上一篇:
使用keyBy对无界数据流进行分区
下一篇:
实验01-数据定义
文档导航

 浙ICP备案2024056857号
浙ICP备案2024056857号
 浙公网安备33020502001085号
浙公网安备33020502001085号