大数据学习
bigdata learning
Toggle navigation
大数据学习
主页
openGauss数据库
Flume
MongoDB
Hadoop
数据库实验
Kafka
Zookeeper
Hbase
Manual
Spark
Neo4j
InfluxDB
RabbitMQ
Flink
About Me
归档
标签
使用Window对无界数据流进行时间分窗
无
2024-04-13 14:00:04
37
0
0
bigdata
### 使用`Window`对无界数据流进行时间分窗 > Written by 黄俊仁,2024/04/13 如下示例用于统计从自定义数据源 `NBUSource` 中接收到的单词出现的次数。通过使用 `Splitter` 类实现的 `flatMap` 方法,程序将接收到的字符串拆分成单词,并为每个单词创建一个包含单词和计数 1 的元组。接着,它通过 `keyBy` 方法按单词分组,并应用了一个基于时间的窗口(每 5 秒一个窗口),在这个窗口内对每个单词的出现次数进行累加。 ```java package org.nbubigdata.flink; import org.apache.flink.api.common.functions.FlatMapFunction; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.windowing.time.Time; import org.apache.flink.util.Collector; public class StreamWindow { public static void main(String[] args) throws Exception { //获取执行环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); //获取自定义的数据流 DataStream<Tuple2<String, Integer>> dataStream = env.addSource(new NBUSource()) .flatMap(new Splitter()) .keyBy(0) .timeWindow(Time.seconds(5)) .sum(1); //打印数据到控制台 //System.out.println(env.getExecutionPlan()); dataStream.print(); //执行任务操作。因为flink是懒加载的,所以必须调用execute方法才会执行 env.execute("WordCount"); } //使用FlatMapFunction函数分割字符串 public static class Splitter implements FlatMapFunction<String, Tuple2<String, Integer>> { @Override public void flatMap(String sentence, Collector<Tuple2<String, Integer>> out) throws Exception { for (String word : sentence.split(" ")) { out.collect(new Tuple2<String, Integer>(word, 1)); } } } } ``` 由于数据流的产生间隔为200毫秒,在每个5秒的时间窗口内一般会总计输出25个单词。运行上述程序,可以在控制台中观察到如下的输出信息,在第1个时间窗口内共输出了19个单词,在第2、3个时间窗口内都正常输出了25个单词。 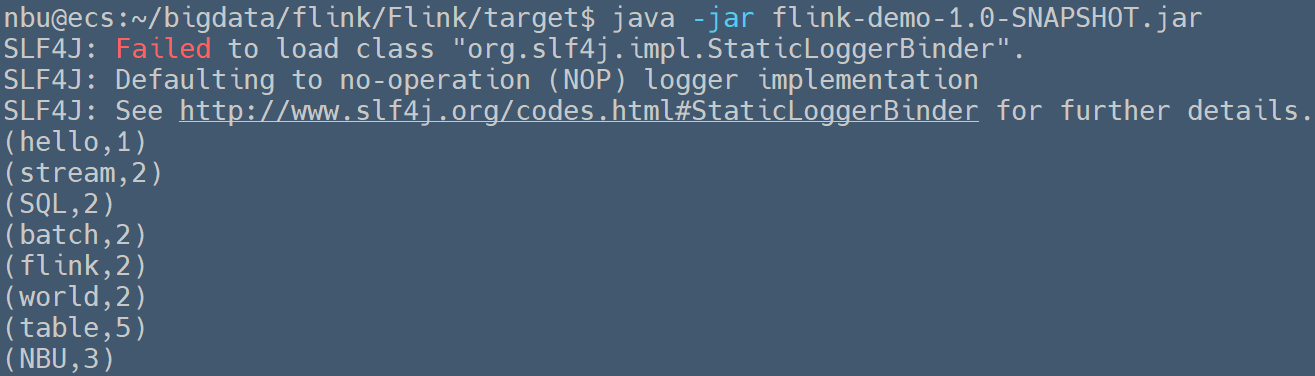 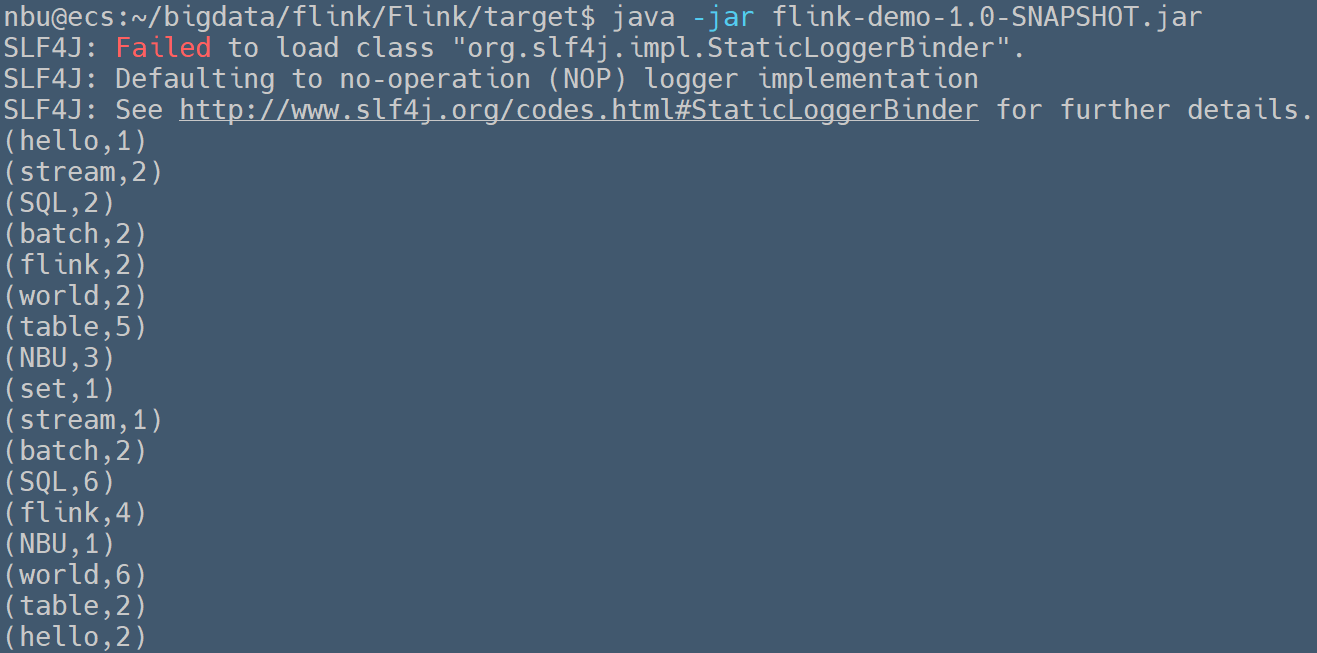 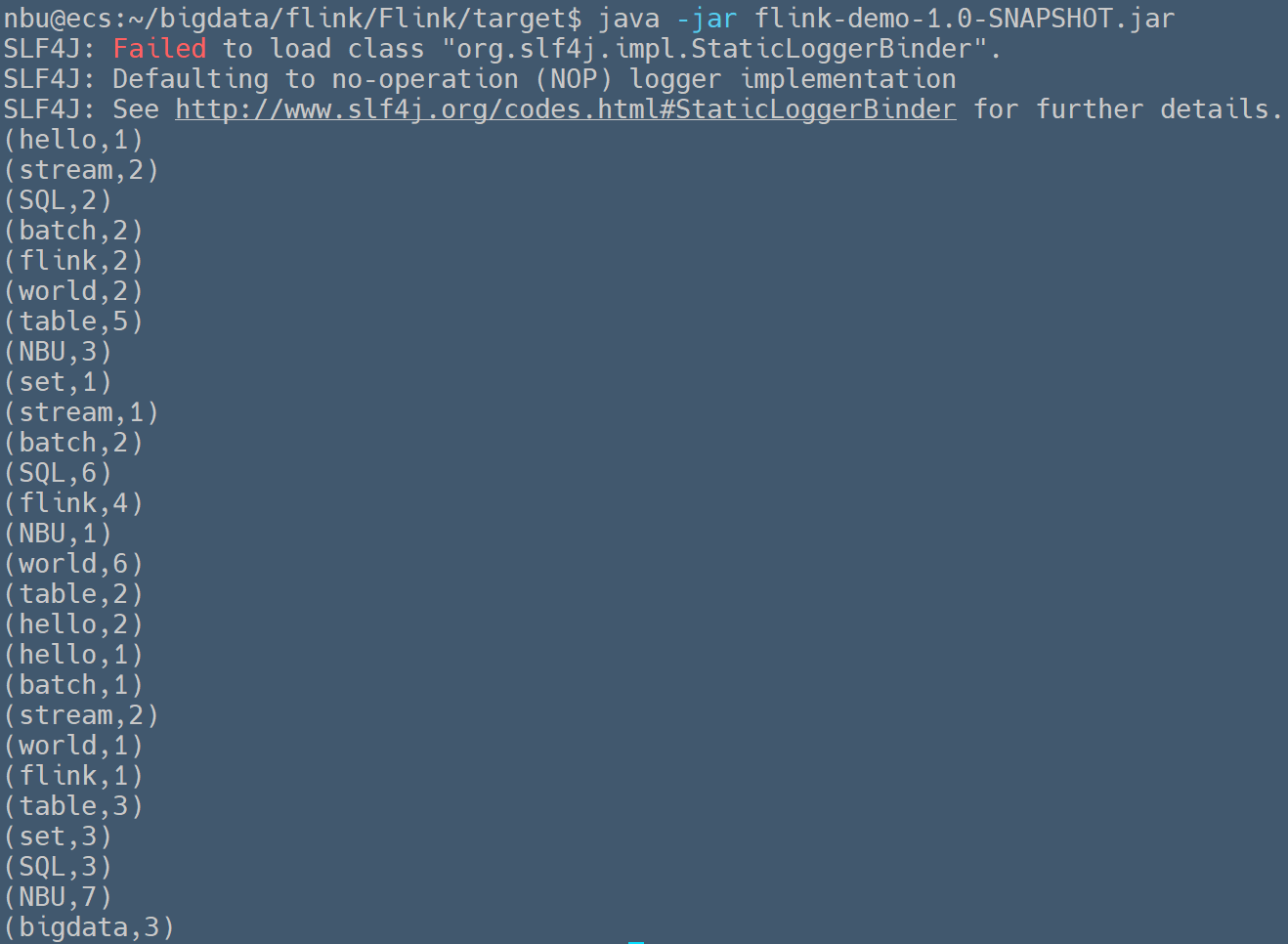
上一篇:
使用WindowAll定义全局窗口
下一篇:
使用keyBy对无界数据流进行分区
文档导航

 浙ICP备案2024056857号
浙ICP备案2024056857号
 浙公网安备33020502001085号
浙公网安备33020502001085号