大数据学习
bigdata learning
Toggle navigation
大数据学习
主页
openGauss数据库
Flume
MongoDB
Hadoop
数据库实验
Kafka
Zookeeper
Hbase
Manual
Spark
Neo4j
InfluxDB
RabbitMQ
Flink
About Me
归档
标签
0RabbitMQ安装
无
2024-02-16 12:20:44
42
0
0
bigdata
#RabbitMQ教程 RabbitMQ 是一个开源的消息队列系统,它基于AMQP(高级消息队列协议)标准设计。消息队列允许应用程序异步地发送和接收数据,这意味着消息发送者不需要等待消息接收者处理信息,从而提高了应用程序的处理效率和扩展性。 ## 安装Rabbitmq及用户管理 ### 安装 #### 1.使用docker查询rabbitmq的镜像 > docker search rabbitmq #### 2.安装镜像 >默认最新版本 > docker pull rabbitmq >如果需要安装其他版本在rabbitmq后面跟上版本号即可 >docker pull rabbitmq:3.7.7-management #### 3.根据下载的镜像创建和启动容器 >docker run -d --hostname my-rabbit --name rabbit -p 15672:15672 -p 5673:5672 rabbitmq ``` -d 后台运行容器; --name 指定容器名; -p 指定服务运行的端口(5672:应用访问端口;15672:控制台Web端口号); -v 映射目录或文件; --hostname 主机名(RabbitMQ的一个重要注意事项是它根据所谓的 “节点名称” 存储数据,默认为主机名); -e 指定环境变量;(RABBITMQ_DEFAULT_VHOST:默认虚拟机名;RABBITMQ_DEFAULT_USER:默认的用户名; RABBITMQ_DEFAULT_PASS:默认用户名的密码 ``` #### 4.查看正在运行容器 >docker ps #### 5.进入容器内部 >docker exec -it 容器id /bin/bssh #### 6.运行 >rabbitmq-plugins enable rabbitmq_management #### 7.浏览器运行 http://localhost:15672/  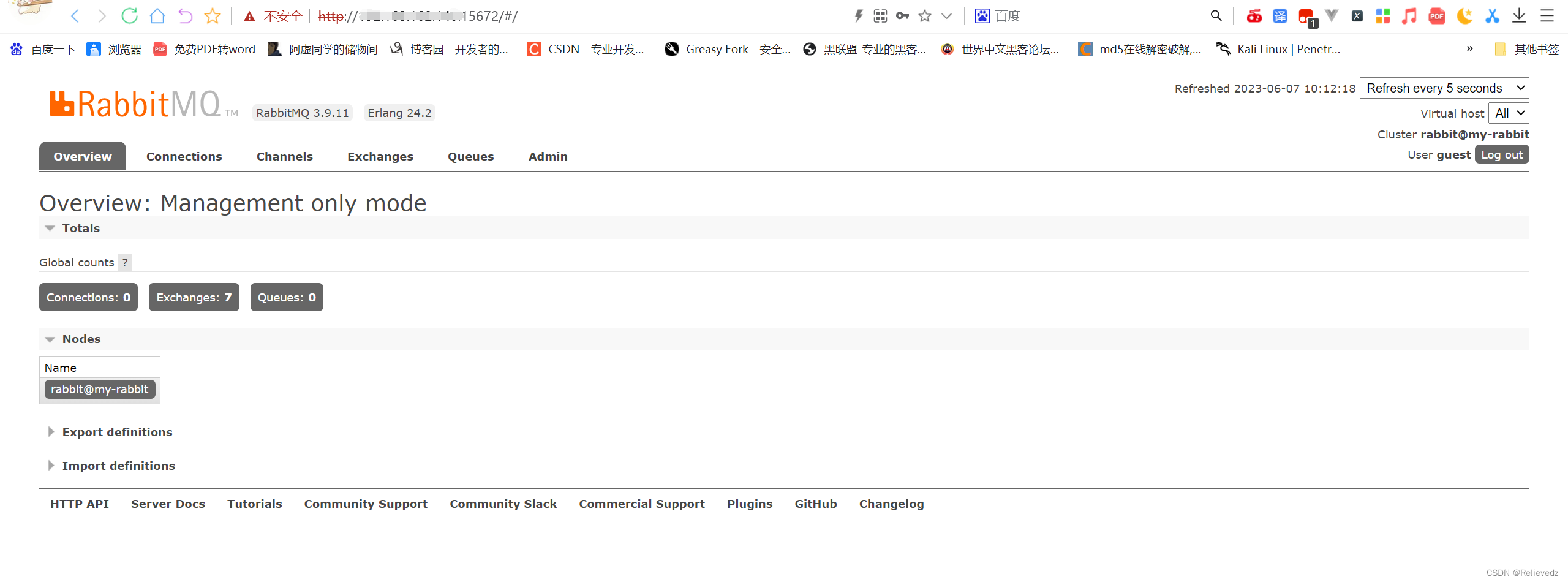 ###RabbitMQ核心概念 RabbitMQ是一个功能强大的开源消息代理(Message Broker),它实现了高度可靠的消息传递模式。理解以下核心概念对于使用RabbitMQ至关重要: ``` 1. 消息(Message): - 消息是在应用程序之间传递的数据单元。它可以包含任何类型的信息,例如文本、JSON、XML等。 - 消息由生产者发送到RabbitMQ,然后由消费者接收和处理。 2. 生产者(Producer): - 生产者是发送消息到RabbitMQ的应用程序。 - 生产者将消息发布到交换机(Exchange),并指定路由键(Routing Key)。 3. 消费者(Consumer): - 消费者是从RabbitMQ接收消息并进行处理的应用程序。 - 消费者订阅特定的队列,并从队列中接收消息。 4. 队列(Queue): - 队列是RabbitMQ用于存储消息的数据结构。 - 消费者从队列中接收消息,并按照顺序进行处理。 - 队列可以是持久化的,这意味着即使RabbitMQ重启,队列中的消息也不会丢失。 5. 交换机(Exchange): - 交换机是消息从生产者发送到队列的路由器。 - 生产者将消息发布到交换机,并指定路由键。 - 交换机根据路由键将消息路由到一个或多个队列。 6. 绑定(Binding): - 绑定是交换机和队列之间的关联关系。 - 它定义了特定的路由规则,使交换机能够将消息路由到绑定的队列。 7. 虚拟主机(Virtual Host): - 虚拟主机是RabbitMQ中用于隔离不同应用程序的逻辑分组。 - 每个虚拟主机都有自己独立的交换机、队列和访问权限。 ``` ###RabbitMQ架构 ``` 1.Publish-生产者(发布消息到RabbitMQ中的Exchange) 2.Exchange-交换机(与生产者建立连接并接收生产者的消息) 3.Routes-路由(交换机以什么样的策略消息发布到Queue) 4.Queue-队列(Exchange会将消息分发到指定的Queue,Queue和消费者进行交互) 5.Consumer-消费者(监听RabbitMQ中的Queue中的消息) ``` 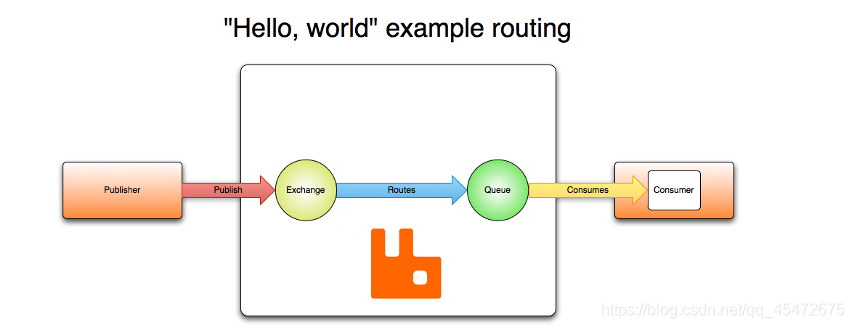 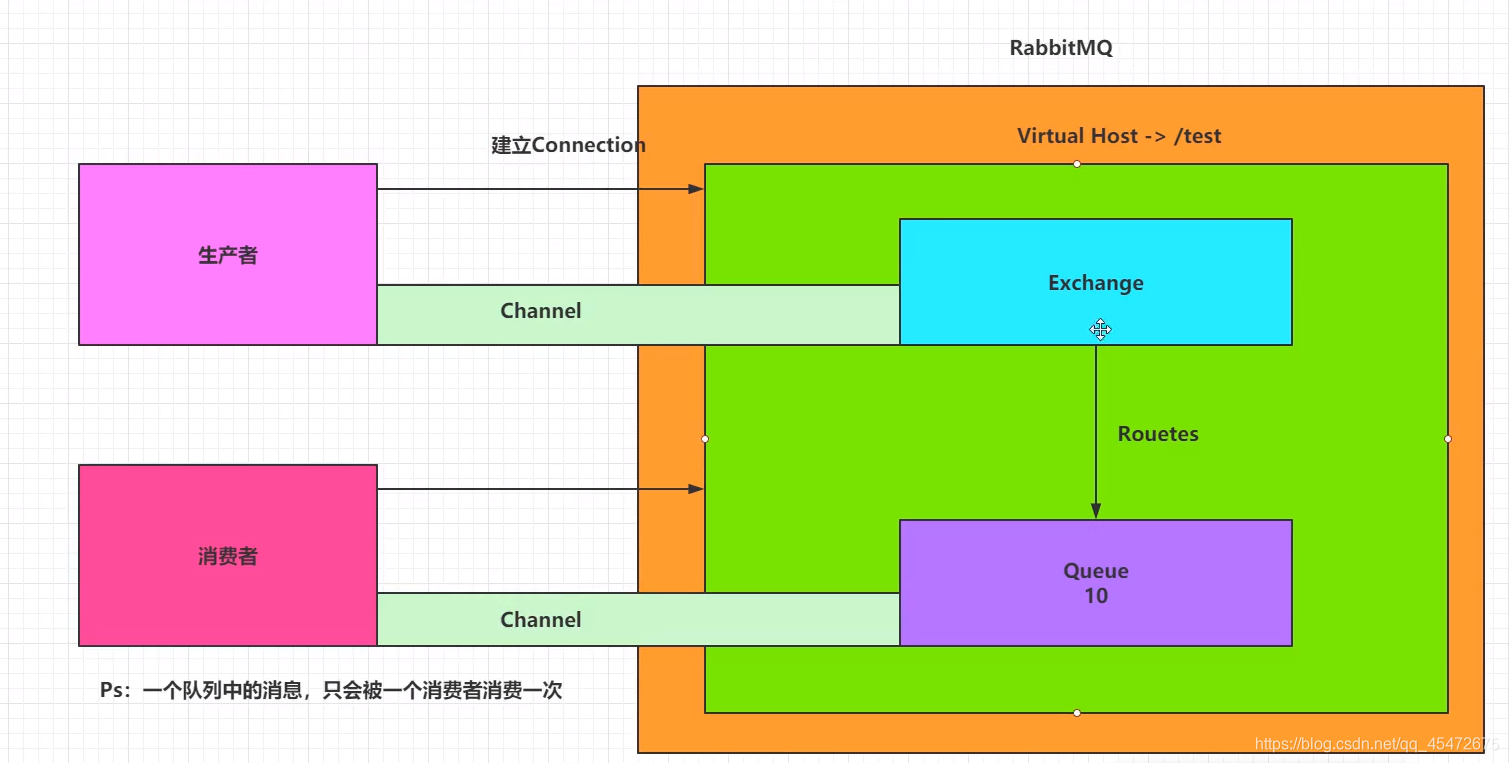 ###使用python与rabbitmq交互 在Python中与RabbitMQ交互,我们将使用pika库,它是RabbitMQ官方推荐的AMQP客户端库。 #####安装 pika ``` pip install pika ``` ####发送消息 ``` # producer.py import pika # 连接到RabbitMQ服务器 connection = pika.BlockingConnection(pika.ConnectionParameters('localhost')) channel = connection.channel() # 创建一个名为'hello'的队列 channel.queue_declare(queue='hello') # 向名为'hello'的队列发送消息 channel.basic_publish(exchange='', routing_key='hello', body='Hello World!') print(" [x] Sent 'Hello World!'") connection.close() ``` ####接受消息 ``` # consumer.py import pika def callback(ch, method, properties, body): print(f" [x] Received {body}") # 连接到RabbitMQ服务器 connection = pika.BlockingConnection(pika.ConnectionParameters('localhost')) channel = connection.channel() # 从'hello'队列接收消息 channel.queue_declare(queue='hello') # 订阅队列,所以当消息到达时,`callback`函数会被调用 channel.basic_consume(queue='hello', on_message_callback=callback, auto_ack=True) print(' [*] Waiting for messages. To exit press CTRL+C') channel.start_consuming() ``` ###使用python示例rabbitmq的5种消息模型 ####基本消息模型(Simple Mode) 这是最基本的消息模型,其中生产者将消息发送到队列,消费者从队列中获取消息并处理。整个过程只有一个生产者,一个默认的交换机,一个队列,一个消费者。 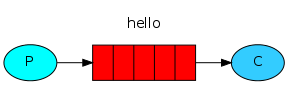 1、创建生产者,创建一个channel,发送消息到exchange,指定路由规则。 ``` import pika # 连接到RabbitMQ服务器 connection = pika.BlockingConnection(pika.ConnectionParameters('localhost')) channel = connection.channel() # 声明队列 channel.queue_declare(queue='hello') # 发送消息 channel.basic_publish(exchange='', routing_key='hello', body='Hello, RabbitMQ!') print("消息已发送") # 关闭连接 connection.close() ``` 2、创建一个消费者,创建一个channel,创建一个队列,并且消费队列 ``` import pika # 连接到RabbitMQ服务器 connection = pika.BlockingConnection(pika.ConnectionParameters('localhost')) channel = connection.channel() # 声明队列 channel.queue_declare(queue='hello') # 定义消息处理函数 def callback(ch, method, properties, body): print("接收到消息:", body) # 消费消息 channel.basic_consume(queue='hello', on_message_callback=callback, auto_ack=True) print("等待消息...") # 开始消费 channel.start_consuming() ``` ####工作队列模式(Work Queue Mode) 在这个模型中,生产者将消息发送到队列,多个消费者从队列中获取消息并处理。每个消息只能被一个消费者处理,这可以实现任务的并行处理。整个过程有一个生产者,一个默认的交换机,一个队列,多个消费者。 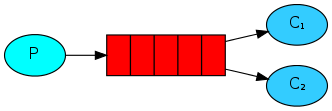 生产者脚本将发送一条任务到名为"task_queue"的队列中 ``` import pika # 连接到RabbitMQ服务器 connection = pika.BlockingConnection(pika.ConnectionParameters('localhost')) channel = connection.channel() # 声明队列 channel.queue_declare(queue='task_queue', durable=True) # 设置队列为持久化 # 发送消息 message = 'Hello, RabbitMQ!' channel.basic_publish(exchange='', routing_key='task_queue', body=message, properties=pika.BasicProperties( delivery_mode=2 # 设置消息持久化 )) print("消息已发送:", message) # 关闭连接 connection.close() ``` 消费者脚本将从同一个队列中接收到任务,并模拟处理任务的时间,然后打印出任务的完成状态。通过设置channel.basic_qos(prefetch_count=1),消费者可以实现公平调度,确保每个消费者一次只处理一个任务,从而实现任务的负载均衡。 ``` import pika import time # 连接到RabbitMQ服务器 connection = pika.BlockingConnection(pika.ConnectionParameters('localhost')) channel = connection.channel() # 声明队列 channel.queue_declare(queue='task_queue', durable=True) # 设置队列为持久化 # 定义消息处理函数 def callback(ch, method, properties, body): print("接收到任务:", body) time.sleep(2) # 模拟任务处理时间 print("完成任务:", body) ch.basic_ack(delivery_tag=method.delivery_tag) # 发送消息确认 # 设置公平调度(Fair Dispatch) channel.basic_qos(prefetch_count=1) # 消费消息 channel.basic_consume(queue='task_queue', on_message_callback=callback) print("等待任务...") # 开始消费 channel.start_consuming() ``` ###发布/订阅模式(Publish/Subscribe Mode) 在这个模型中,生产者将消息发送到交换器(Exchange),交换器将消息广播到多个队列,每个队列绑定到交换器上。每个消费者都可以从自己的队列中获取消息并处理。 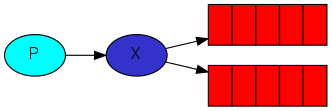 发布者脚本将发布一条消息到名为"logs"的交换机中,路由键为空(因为在发布订阅模式中,交换机会将消息广播给所有与之绑定的队列)。 ``` import pika # 连接到RabbitMQ服务器 connection = pika.BlockingConnection(pika.ConnectionParameters('localhost')) channel = connection.channel() # 声明交换机(Exchange) channel.exchange_declare(exchange='logs', exchange_type='fanout') # 发布消息 message = 'Hello, RabbitMQ!' channel.basic_publish(exchange='logs', routing_key='', body=message) print("消息已发布:", message) # 关闭连接 connection.close() ``` 订阅者脚本将创建一个临时队列,并将该队列绑定到"logs"交换机。当有消息发布到交换机时,订阅者将接收到消息并打印出来。 ``` import pika # 连接到RabbitMQ服务器 connection = pika.BlockingConnection(pika.ConnectionParameters('localhost')) channel = connection.channel() # 声明交换机(Exchange) channel.exchange_declare(exchange='logs', exchange_type='fanout') # 创建一个临时队列 result = channel.queue_declare(queue='', exclusive=True) queue_name = result.method.queue # 将队列绑定到交换机 channel.queue_bind(exchange='logs', queue=queue_name) # 定义消息处理函数 def callback(ch, method, properties, body): print("接收到消息:", body) # 消费消息 channel.basic_consume(queue=queue_name, on_message_callback=callback, auto_ack=True) print("等待消息...") # 开始消费 channel.start_consuming() ``` ###路由模式 在这个模型中,生产者将消息发送到交换器,交换器根据消息的路由键(Routing Key)将消息发送到绑定到交换器上的特定队列。消费者根据自己关心的路由键绑定到队列上,只接收符合自己关心的路由键的消息。  生产者脚本将发送一条消息到名为"direct_logs"的交换机中,同时指定一个路由键(例如,'info')。 ``` import pika # 连接到RabbitMQ服务器 connection = pika.BlockingConnection(pika.ConnectionParameters('localhost')) channel = connection.channel() # 声明交换机(Exchange) channel.exchange_declare(exchange='direct_logs', exchange_type='direct') # 发送消息 message = 'Hello, RabbitMQ!' routing_key = 'info' # 设置路由键 channel.basic_publish(exchange='direct_logs', routing_key=routing_key, body=message) print("消息已发送:", message) # 关闭连接 connection.close() ``` 消费者脚本将创建一个临时队列,并将队列绑定到交换机,并指定要接收的路由键(例如,'info'和'error')。当有消息发布到交换机并且路由键与队列绑定的路由键匹配时,消费者将接收到消息并打印出来。 ``` import pika # 连接到RabbitMQ服务器 connection = pika.BlockingConnection(pika.ConnectionParameters('localhost')) channel = connection.channel() # 声明交换机(Exchange) channel.exchange_declare(exchange='direct_logs', exchange_type='direct') # 创建一个临时队列 result = channel.queue_declare(queue='', exclusive=True) queue_name = result.method.queue # 设置需要接收的路由键 routing_keys = ['info', 'error'] # 可以根据需要设置多个路由键 # 将队列绑定到交换机,并指定路由键 for routing_key in routing_keys: channel.queue_bind(exchange='direct_logs', queue=queue_name, routing_key=routing_key) # 定义消息处理函数 def callback(ch, method, properties, body): print("接收到消息:", body) # 消费消息 channel.basic_consume(queue=queue_name, on_message_callback=callback, auto_ack=True) print("等待消息...") # 开始消费 channel.start_consuming() ``` ###主题模式 在这个模型中,生产者将消息发送到交换器,交换器根据消息的路由键和通配符模式将消息发送到符合匹配规则的队列。消费者根据自己关心的通配符模式绑定到队列上,只接收符合自己关心的消息。 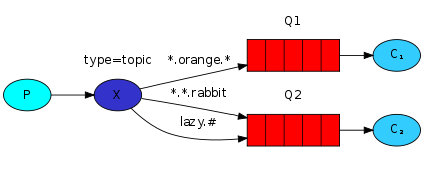 生产者脚本将发送一条消息到名为"topic_logs"的交换机中,同时指定一个路由键(例如,'log.info')。 ``` import pika # 连接到RabbitMQ服务器 connection = pika.BlockingConnection(pika.ConnectionParameters('localhost')) channel = connection.channel() # 声明交换机(Exchange) channel.exchange_declare(exchange='topic_logs', exchange_type='topic') # 发送消息 message = 'Hello, RabbitMQ!' routing_key = 'log.info' # 设置路由键,可以使用通配符匹配规则 channel.basic_publish(exchange='topic_logs', routing_key=routing_key, body=message) print("消息已发送:", message) # 关闭连接 connection.close() ``` 消费者脚本将创建一个临时队列,并将队列绑定到交换机,并指定要接收的主题匹配规则(例如,'log.'和'.info')。当有消息发布到交换机并且路由键与队列绑定的匹配规则匹配时,消费者将接收到消息并打印出来。 ``` import pika # 连接到RabbitMQ服务器 connection = pika.BlockingConnection(pika.ConnectionParameters('localhost')) channel = connection.channel() # 声明交换机(Exchange) channel.exchange_declare(exchange='topic_logs', exchange_type='topic') # 创建一个临时队列 result = channel.queue_declare(queue='', exclusive=True) queue_name = result.method.queue # 设置需要接收的主题匹配规则 binding_keys = ['log.*', '*.info'] # 可以根据需要设置多个匹配规则 # 将队列绑定到交换机,并指定匹配规则 for binding_key in binding_keys: channel.queue_bind(exchange='topic_logs', queue=queue_name, routing_key=binding_key) # 定义消息处理函数 def callback(ch, method, properties, body): print("接收到消息:", body) # 消费消息 channel.basic_consume(queue=queue_name, on_message_callback=callback, auto_ack=True) print("等待消息...") # 开始消费 channel.start_consuming() ```
上一篇:
09-Zookeeper权限控制
下一篇:
1 安装
文档导航

 浙ICP备案2024056857号
浙ICP备案2024056857号
 浙公网安备33020502001085号
浙公网安备33020502001085号