大数据学习
bigdata learning
Toggle navigation
大数据学习
主页
openGauss数据库
Flume
MongoDB
Hadoop
数据库实验
Kafka
Zookeeper
Hbase
Manual
Spark
Neo4j
InfluxDB
RabbitMQ
Flink
About Me
归档
标签
06-Zookeeper-session基本原理
Zookeeper
2022-10-17 19:47:21
35
0
0
bigdata
Zookeeper
客户端与服务端之间的连接是基于 TCP 长连接,client 端连接 server 端默认的 2181 端口,也就是 session 会话。 从第一次连接建立开始,客户端开始会话的生命周期,客户端向服务端的 ping 包请求,每个会话都可以设置一个超时时间。 # Session 的创建 **sessionID**: 会话 ID,用来唯一标识一个会话,每次客户端创建会话的时候,zookeeper 都会为其分配一个全局唯一的 sessionID。zookeeper 创建 sessionID 类 SessionTrackerImpl 中的源码。 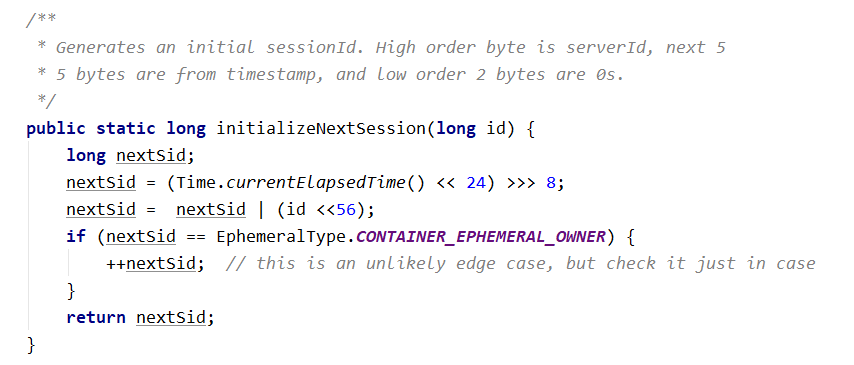 **Timeout**:会话超时时间。客户端在构造 Zookeeper 实例时候,向服务端发送配置的超时时间,server 端会根据自己的超时时间限制最终确认会话的超时时间。 **TickTime**:下次会话超时时间点,默认 2000 毫秒。可在 zoo.cfg 配置文件中配置,便于 server 端对 session 会话实行**分桶策略管理**。 **isClosing**:该属性标记一个会话是否已经被关闭,当 server 端检测到会话已经超时失效,该会话标记为 "已关闭",不再处理该会话的新请求。 # Session 的状态 下面介绍几个重要的状态: * **connecting**:连接中,session 一旦建立,状态就是 connecting 状态,时间很短。 * **connected**:已连接,连接成功之后的状态。 * **closed**:已关闭,发生在 session 过期,一般由于网络故障客户端重连失败,服务器宕机或者客户端主动断开。 # 会话超时管理(分桶策略 + 会话激活) zookeeper 的 leader 服务器再运行期间定时进行会话超时检查,时间间隔是 ExpirationInterval,单位是毫秒,默认值是 tickTime,每隔 tickTime 进行一次会话超时检查。 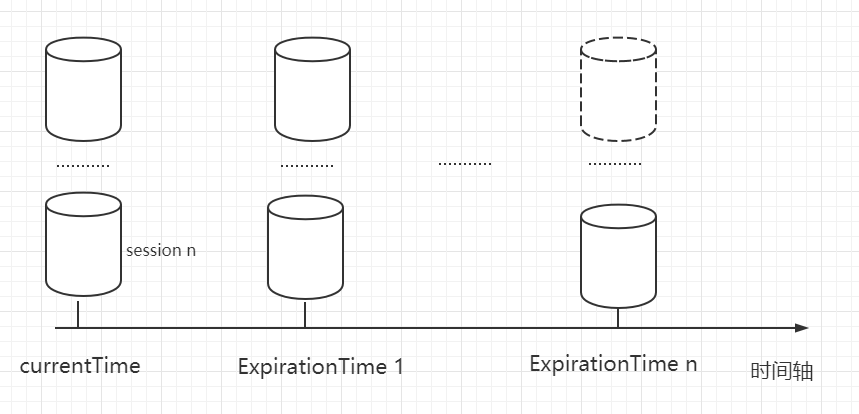 ExpirationTime 的计算方式: ```java ExpirationTime = CurrentTime + SessionTimeout; ExpirationTime = (ExpirationTime / ExpirationInterval + 1) * ExpirationInterval; ``` 在 zookeeper 运行过程中,客户端会在会话超时过期范围内向服务器发送请求(包括读和写)或者 ping 请求,俗称**心跳检测**完成会话激活,从而来保持会话的有效性。 会话激活流程: 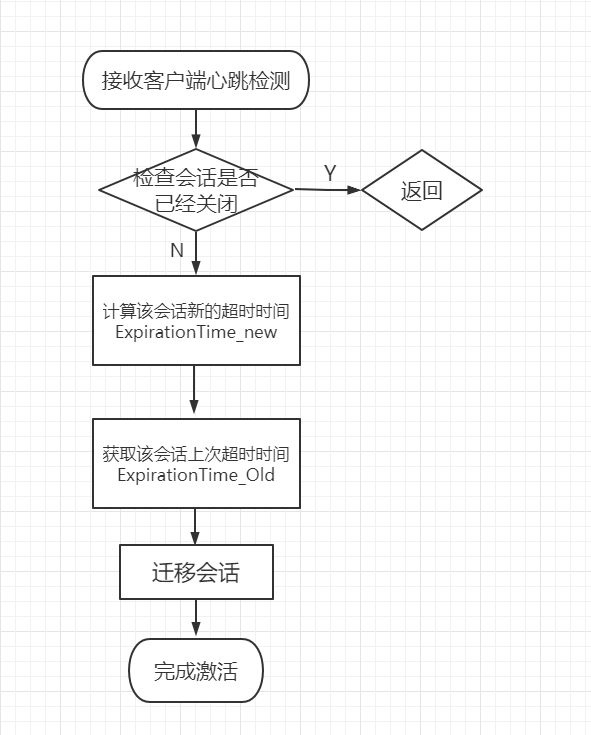 激活后进行迁移会话的过程,然后开始新一轮: 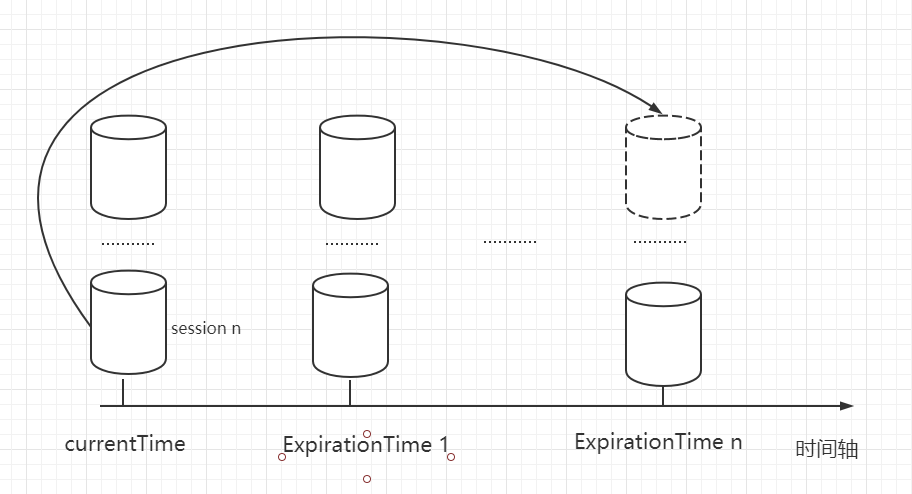
上一篇:
06-Spark常见问题-解决方法
下一篇:
07 openGauss数据库日志管理指导手册
文档导航

 浙ICP备案2024056857号
浙ICP备案2024056857号
 浙公网安备33020502001085号
浙公网安备33020502001085号